
5 librerías Python para automatizar informes ejecutivos con IA

La generación periódica de informes ejecutivos es una tarea crítica en el entorno profesional que consume un tiempo considerable cuando se realiza de forma manual. Sin embargo, cualquier proceso sistemático que dependa de reglas lógicas es un candidato idóneo para ser automatizado de extremo a extremo.
Python permite unificar flujos de alta complejidad en un único proceso: desde la ingesta y transformación de datos, hasta la generación de gráficos analíticos, la redacción de conclusiones mediante Inteligencia Artificial y la maquetación final en un documento listo para su distribución.
En este artículo analizamos las cinco librerías que consideramos esenciales para construir este ecosistema.
1. Pandas: el motor de procesamiento de datos
En la automatización de documentos, pandas actúa como el motor de ingesta, limpieza y transformación de datos. Aunque Python permite gestionar información con estructuras nativas como listas o diccionarios, estas se vuelven ineficientes y difíciles de mantener al escalar.
pandas introduce el DataFrame: una estructura bidimensional indexada que permite operaciones vectorizadas (sin bucles for), indexación alineada automáticamente y uniones complejas en una sola línea de código.
Conexión a bases de datos con read_sql_query
La información que alimentará el informe suele residir en bases de datos SQL. Con read_sql_query podemos volcar directamente sobre un DataFrame el resultado de una consulta, manteniendo nombre, formato y tipo de dato de cada columna.
import pandas as pd
query_informe = """
SELECT
id_producto,
categoria,
SUM(cantidad) AS total_vendido,
SUM(total_linea) AS ingresos
FROM ventas
WHERE fecha_venta >= ?
GROUP BY id_producto, categoria;
"""
df_ventas_sql = pd.read_sql_query(
query_informe,
conexion_base_de_datos,
params=['01-01-2026']
)
Acceso a los datos del DataFrame
# Ordenar de mayor a menor ingreso
df_ventas_sql.sort_values(by='ingresos', ascending=False, inplace=True)
# Extraer el ID del producto líder (fila 0, columna 0)
producto_top = df_ventas_sql.iloc[0, 0]
# Extraer los ingresos del producto con menor rendimiento (última fila, columna 3)
peor_ingreso = df_ventas_sql.iloc[-1, 3]
# Subconjunto: 3 primeras filas, columnas 'id_producto' y 'categoria'
top_3_productos = df_ventas_sql.iloc[0:3, 0:2]
# Valor de 'ingresos' para un 'id_producto' específico
ingresos_producto = df_ventas_sql.loc[
df_ventas_sql['id_producto'] == 'PROD-1024', 'ingresos'
].values[0]
Operaciones matemáticas y estadísticas
# Agregaciones globales
total_ingresos_global = df_ventas_sql['ingresos'].sum()
promedio_unidades = df_ventas_sql['total_vendido'].mean()
# Percentiles y distribución
mediana_ingresos = df_ventas_sql['ingresos'].quantile(0.5)
umbral_top_25 = df_ventas_sql['ingresos'].quantile(0.75)
# Precio medio unitario vectorizado
df_ventas_sql['precio_medio_unitario'] = (
df_ventas_sql['ingresos'] / df_ventas_sql['total_vendido']
).round(2)
# Resumen estadístico automatizado (media, desviación, mínimos, máximos)
resumen_estadistico = df_ventas_sql[['total_vendido', 'ingresos']].describe()
2. python-docx: el maquetador del documento final
Si pandas es el cerebro analítico, python-docx es el componente que traslada esos resultados al formato nativo de Microsoft Word (.docx). Su verdadero potencial no radica en maquetar páginas en blanco, sino en manipular plantillas predefinidas: se diseña un documento base en Word con los estilos corporativos y logotipos de la empresa, y el código se encarga únicamente de buscar marcadores de posición e inyectar dinámicamente textos, gráficos y tablas.
Gestión de párrafos, estilos y runs
En python-docx, un párrafo se divide en runs (secuencias de texto con el mismo formato). Para cambiar el estilo de una sola palabra dentro de una frase —por ejemplo, resaltar un KPI— se añade el texto a través de estos bloques específicos.
from docx import Document
from docx.shared import Inches, Pt
from docx.enum.text import WD_ALIGN_PARAGRAPH
# Inicializar el documento (o cargar una plantilla: Document('plantilla.docx'))
doc = Document()
# Título principal centrado
titulo = doc.add_heading('Informe Ejecutivo de Rendimiento Comercial', level=1)
titulo.alignment = WD_ALIGN_PARAGRAPH.CENTER
# Párrafo con fragmento en negrita mediante run
parrafo_intro = doc.add_paragraph(
'A continuación se presentan los resultados analíticos de la campaña. '
)
run_destacado = parrafo_intro.add_run(
'Es crítico destacar que los objetivos globales se han cumplido.'
)
run_destacado.bold = True
run_destacado.font.size = Pt(11)
Inserción dinámica de imágenes
El flujo consiste en guardar el gráfico como archivo .png y luego incrustarlo definiendo el ancho para que la proporción se escale automáticamente.
doc.add_heading('Visualización de Ingresos por Categoría', level=2)
doc.add_picture('grafico_ingresos.png', width=Inches(6.0))
pie_foto = doc.add_paragraph(
'Figura 1.1: Distribución de ingresos vectorizados por familia de producto.'
)
pie_foto.alignment = WD_ALIGN_PARAGRAPH.CENTER
Volcado automático de DataFrames a tablas Word
# 1. Dimensiones: filas = datos + cabecera, columnas = campos del DataFrame
num_filas = df_ventas_sql.shape[0] + 1
num_columnas = df_ventas_sql.shape[1]
# 2. Crear la estructura de tabla con estilo nativo de Word
tabla = doc.add_table(rows=num_filas, cols=num_columnas)
tabla.style = 'Light Shading Accent 1'
# 3. Cabecera
hdr_cells = tabla.rows[0].cells
for i, nombre_col in enumerate(df_ventas_sql.columns):
hdr_cells[i].text = str(nombre_col).replace('_', ' ').title()
# 4. Filas de datos
for fila_idx in range(df_ventas_sql.shape[0]):
row_cells = tabla.rows[fila_idx + 1].cells
for col_idx in range(num_columnas):
row_cells[col_idx].text = str(df_ventas_sql.iat[fila_idx, col_idx])
# 5. Guardar el documento
doc.save('Informe_Final_Ventas.docx')
3. Matplotlib: la traducción visual de los datos
Un informe compuesto exclusivamente por texto y tablas densas satura al lector ejecutivo. matplotlib convierte las métricas abstractas de pandas en gráficos de alto impacto que permiten identificar tendencias, anomalías y rendimientos en segundos.
En un ecosistema de automatización, matplotlib actúa en modo silencioso: modela el gráfico, aplica los estilos corporativos y lo exporta como imagen estática de alta resolución. Después, python-docx lo incrusta en el documento.
Gráfico de barras: comparativa de ingresos por categoría
import matplotlib
matplotlib.use('Agg') # Backend sin interfaz gráfica para entornos automatizados
import matplotlib.pyplot as plt
# 1. Agrupar datos por categoría
df_grafico = df_ventas_sql.groupby('categoria')['ingresos'].sum().reset_index()
df_grafico.sort_values(by='ingresos', ascending=True, inplace=True)
# 2. Inicializar figura
fig, ax = plt.subplots(figsize=(7, 4))
# 3. Barras horizontales
barras = ax.barh(
df_grafico['categoria'],
df_grafico['ingresos'],
color='#1f77b4',
edgecolor='none'
)
# 4. Estilo corporativo
ax.set_title(
'Distribución de Ingresos Globales por Categoría',
fontsize=12, pad=15, fontweight='bold', color='#333333'
)
ax.set_xlabel('Ingresos Acumulados (€)', fontsize=10, labelpad=10, color='#555555')
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['left'].set_color('#cccccc')
ax.spines['bottom'].set_color('#cccccc')
ax.grid(axis='x', linestyle='--', alpha=0.5)
# 5. Exportar a disco
plt.tight_layout()
plt.savefig('grafico_ingresos.png', dpi=300, bbox_inches='tight')
plt.close(fig)
Gráfico de dispersión: correlación entre variables
Cuando el informe requiere cruzar dos métricas para evaluar su correlación —por ejemplo, si un mayor volumen de unidades vendidas se traduce proporcionalmente en mayores ingresos— el scatter plot ofrece la perspectiva técnica idónea. python
fig, ax = plt.subplots(figsize=(7, 4))
ax.scatter(
df_ventas_sql['total_vendido'],
df_ventas_sql['ingresos'],
color='#2ca02c',
alpha=0.7,
edgecolors='w',
s=80
)
# Anotación automática del outlier con mayor ingreso
fila_max = df_ventas_sql.loc[df_ventas_sql['ingresos'] == df_ventas_sql['ingresos'].max()]
if not fila_max.empty:
ax.annotate(
f"Líder: {fila_max['id_producto'].values[0]}",
xy=(fila_max['total_vendido'].values[0], fila_max['ingresos'].values[0]),
xytext=(10, -10),
textcoords='offset points',
fontsize=9,
fontweight='bold',
arrowprops=dict(arrowstyle="->", color='#333333', lw=0.8)
)
ax.set_title(
'Correlación: Volumen de Ventas vs Ingresos por Producto',
fontsize=12, pad=15, fontweight='bold'
)
ax.set_xlabel('Unidades Totales Vendidas', fontsize=10)
ax.set_ylabel('Ingresos Totales (€)', fontsize=10)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.grid(True, linestyle=':', alpha=0.6)
plt.tight_layout()
plt.savefig('grafico_correlacion.png', dpi=300, bbox_inches='tight')
plt.close(fig)
Como expertos en bases de datos, utilizamos
matplotlibpara generar los gráficos analíticos que aparecen en Coyote Monitor, nuestra herramienta de monitorización de instancias SQL. A continuación, algunos ejemplos de lo que se puede conseguir con esta librería:
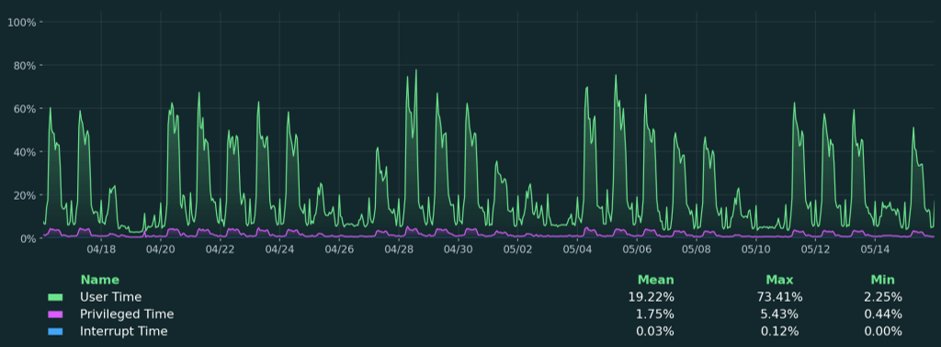
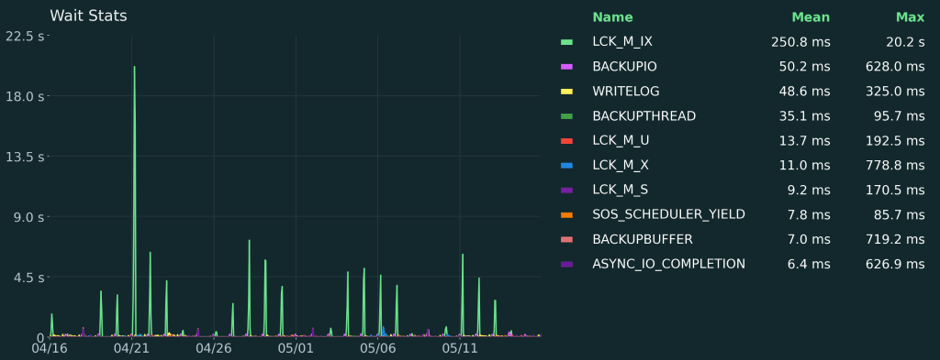
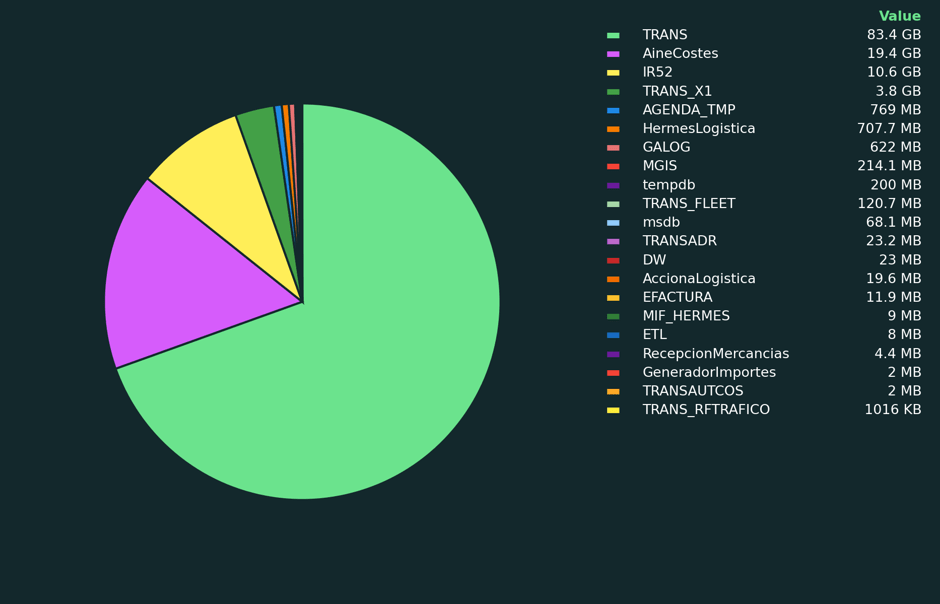
4. Azure OpenAI: el redactor de conclusiones inteligente
Un informe sigue estando incompleto sin la pieza clave: el análisis cualitativo. En un flujo tradicional, un analista debe examinar los resultados para redactar resúmenes ejecutivos, detectar desviaciones y proponer los siguientes pasos.
Azure OpenAI transforma este proceso. Su propósito aquí no es el de un chatbot conversacional, sino el de un motor de síntesis corporativa: alimentando al modelo con los KPIs clave calculados por pandas mediante prompts estructurados, la IA redacta secciones de «Resumen Ejecutivo», «Análisis de Desviaciones» o «Conclusiones» con tono formal y coherente en cuestión de segundos. Al integrarlo vía Azure, se garantiza el cumplimiento de las normativas de privacidad y gobernanza de datos empresariales.
Inicialización del cliente y construcción del contexto
import os
from openai import AzureOpenAI
# 1. Inicializar el cliente con credenciales desde variables de entorno
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key = os.getenv("AZURE_OPENAI_KEY"),
api_version = "2024-02-15-preview"
)
# 2. Extraer métricas clave del DataFrame para construir el contexto del prompt
top_producto_id = df_ventas_sql.iloc[0, 0]
top_producto_ingresos = df_ventas_sql.iloc[0, 3]
total_campaña_ingresos = df_ventas_sql['ingresos'].sum()
contexto_metricas = f"""
- Facturación Total de la Campaña: {total_campaña_ingresos:,.2f} €
- Producto Líder en Ventas (ID): {top_producto_id}
- Ingresos Generados por el Líder: {top_producto_ingresos:,.2f} €
"""
Petición estructurada al modelo
respuesta_ia = client.chat.completions.create(
model="nombre-de-tu-despliegue-en-azure", # Deployment Name en Azure AI Studio
messages=[
{
"role": "system",
"content": (
"Eres un analista financiero de alta dirección. Tu cometido es redactar el resumen "
"ejecutivo formal para el informe mensual del consejo de administración. Sé conciso, "
"utiliza un tono estrictamente profesional y analiza los datos proporcionados "
"sin inventar métricas externas."
)
},
{
"role": "user",
"content": (
f"Redacta un párrafo analítico basado exactamente en los siguientes "
f"KPIs del trimestre:\n{contexto_metricas}"
)
}
],
temperature=0.3 # Temperatura baja para consistencia y mínima creatividad
)
# Extraer el texto generado
texto_conclusiones = respuesta_ia.choices[0].message.content
5. python-dotenv: el guardián de las credenciales
Al conectar el flujo a bases de datos corporativas y a la API de Azure OpenAI, la seguridad se convierte en la máxima prioridad. Una de las vulnerabilidades más comunes es el hardcoding: escribir directamente en el código usuarios, contraseñas y tokens de acceso. Si ese script se sube por error a un repositorio público, la seguridad de toda la organización queda comprometida.
python-dotenv implementa una regla de oro de la ciberseguridad: separar la configuración del código. Almacena todas las credenciales en un archivo local .env, aislado del código fuente. Al ejecutar el script, load_dotenv() carga esos valores en memoria sin que queden escritos en ningún fichero accesible.
Estructura del proyecto
mi_proyecto_automatizacion/ ├── .gitignore ← Excluye el .env de Git ├── .env ← Credenciales locales (nunca se sube al repositorio) └── script_informe.py ← Código fuente limpio y sin secretos
Archivo .env
DB_ENGINE="postgresql" DB_USER="admin_reportes" DB_PASSWORD="PasswordComplejoYAltamenteSeguro2026" DB_HOST="localhost" DB_PORT="5432" DB_NAME="produccion_ventas" AZURE_OPENAI_ENDPOINT="https://mi-recurso-azure.openai.azure.com/" AZURE_OPENAI_KEY="9876543210abcdef9876543210abcdef"
Archivo .gitignore
# Excluir configuraciones locales y credenciales .env
Carga segura en el script
import os
from dotenv import load_dotenv
from sqlalchemy import create_engine
from openai import AzureOpenAI
# 1. Cargar variables del .env en memoria
load_dotenv()
# 2. Construcción segura de la cadena de conexión a la base de datos
db_url = (
f"{os.getenv('DB_ENGINE')}://"
f"{os.getenv('DB_USER')}:{os.getenv('DB_PASSWORD')}@"
f"{os.getenv('DB_HOST')}:{os.getenv('DB_PORT')}/{os.getenv('DB_NAME')}"
)
engine = create_engine(db_url)
# 3. Inicialización del cliente Azure OpenAI sin exponer la API Key en el código
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key = os.getenv("AZURE_OPENAI_KEY"),
api_version = "2024-02-15-preview"
)
Conclusión
La automatización de documentos con Python representa un cambio de paradigma en la eficiencia operativa. Al integrar estas cinco librerías, cada componente cumple un rol estratégico y complementario:
| Librería | Rol en el ecosistema |
|---|---|
pandas | Ingesta, limpieza y transformación de datos |
matplotlib | Generación de visualizaciones analíticas |
python-docx | Maquetación profesional del documento Word |
Azure OpenAI | Redacción automática de análisis cualitativos |
python-dotenv | Seguridad e integridad de las credenciales |
El resultado es un flujo reproducible que elimina el trabajo manual repetitivo y garantiza informes consistentes, precisos y listos para la toma de decisiones.
¿Quieres automatizar los informes de tu organización con Python y Azure?
Este ecosistema de librerías es potente por sí solo, pero alcanza su máximo valor cuando se combina con una arquitectura de datos sólida: fuentes de datos bien estructuradas, modelos semánticos en Microsoft Fabric y capacidades de IA integradas en Azure OpenAI.
En Aleson ITC ayudamos a empresas a construir flujos de Data Analytics y Microsoft Fabric que automatizan desde la ingesta de datos hasta la generación de informes ejecutivos, conectando todo el pipeline bajo el ecosistema Microsoft.
Si tu equipo dedica horas a la semana a consolidar datos y maquetar informes manualmente, podemos ayudarte a diseñar un flujo automatizado adaptado a vuestras necesidades.
FAQ — Preguntas frecuentes sobre automatización de documentos con Python
¿Qué librerías Python se usan para generar documentos Word de forma automática?
La combinación más habitual es pandas para procesar los datos, matplotlib para generar los gráficos y python-docx para ensamblar el documento .docx final. Esta arquitectura permite pasar de datos en bruto a un informe profesional sin intervención manual.
¿Es seguro usar credenciales de bases de datos y APIs en scripts Python?
Solo si se gestionan correctamente. La práctica recomendada es usar python-dotenv para almacenar las credenciales en un archivo .env local, excluido del repositorio mediante .gitignore. Nunca deben escribirse directamente en el código fuente.
¿Qué ventaja tiene usar plantillas .docx frente a generar el documento desde cero?
Las plantillas permiten que el equipo de diseño o comunicación defina los estilos corporativos, encabezados y logotipos una sola vez en Word. El código únicamente busca marcadores de posición e inyecta el contenido dinámico, garantizando consistencia visual sin que los desarrolladores gestionen el diseño.
¿Se puede conectar este flujo a Microsoft Fabric o Power BI?
Sí. pandas puede conectarse a cualquier fuente de datos compatible, incluyendo endpoints de Microsoft Fabric vía SQL o APIs REST. Además, los informes generados pueden complementar los dashboards de Power BI como documentos de distribución ejecutiva.
Si necesitas una arquitectura integrada, el equipo de Data Analytics de Aleson ITC puede ayudarte a diseñarla.