
Variables en Microsoft Fabric: parametrización y despliegue multientorno

En muchos proyectos con Microsoft Fabric, el principal reto no es la ingesta de datos, sino la parametrización y estandarización de la configuración. Cuando los equipos trabajan con múltiples entornos, lakehouses compartidos y pipelines que deben mantenerse coherentes entre desarrollo y producción, la falta de una estrategia clara de gestión de variables genera deuda técnica costosa y errores difíciles de rastrear.
Este artículo muestra cómo resolver ese problema con un patrón probado: Variable Library como capa de configuración central, acceso dinámico a OneLake y despliegues controlados con Deployment Pipelines.
El reto de la parametrización en proyectos multientorno
Los problemas más frecuentes aparecen cuando el proyecto trabaja con:
- Múltiples entornos (DEV / TEST / PROD), cada uno con sus propios recursos, permisos, conexiones y parámetros de configuración.
- Distintos lakehouses y pipelines que comparten lógica común, pero apuntan a orígenes y destinos diferentes según el entorno.
- Equipos distribuidos que necesitan una referencia común para evitar inconsistencias entre capas de desarrollo, pruebas y producción.
Sin una estrategia de parametrización, los notebooks acaban con valores hardcodeados: rutas, IDs, nombres de tablas y conexiones escritos directamente en el código. El resultado es un ciclo de desarrollo frágil donde cada promoción de artefactos entre entornos requiere intervención manual y abre la puerta a errores.
Una solución robusta debe permitir:
- Evitar hardcodes en rutas, IDs, nombres de tablas o conexiones, reduciendo errores al mover artefactos entre entornos.
- Reutilizar notebooks como piezas genéricas de procesamiento donde la lógica permanece estable y solo cambian los valores de configuración.
- Facilitar despliegues seguros y repetibles, especialmente en proyectos que utilizan Deployment Pipelines o procesos de ALM.
Arquitectura de la solución
1. Variable Library como capa de configuración
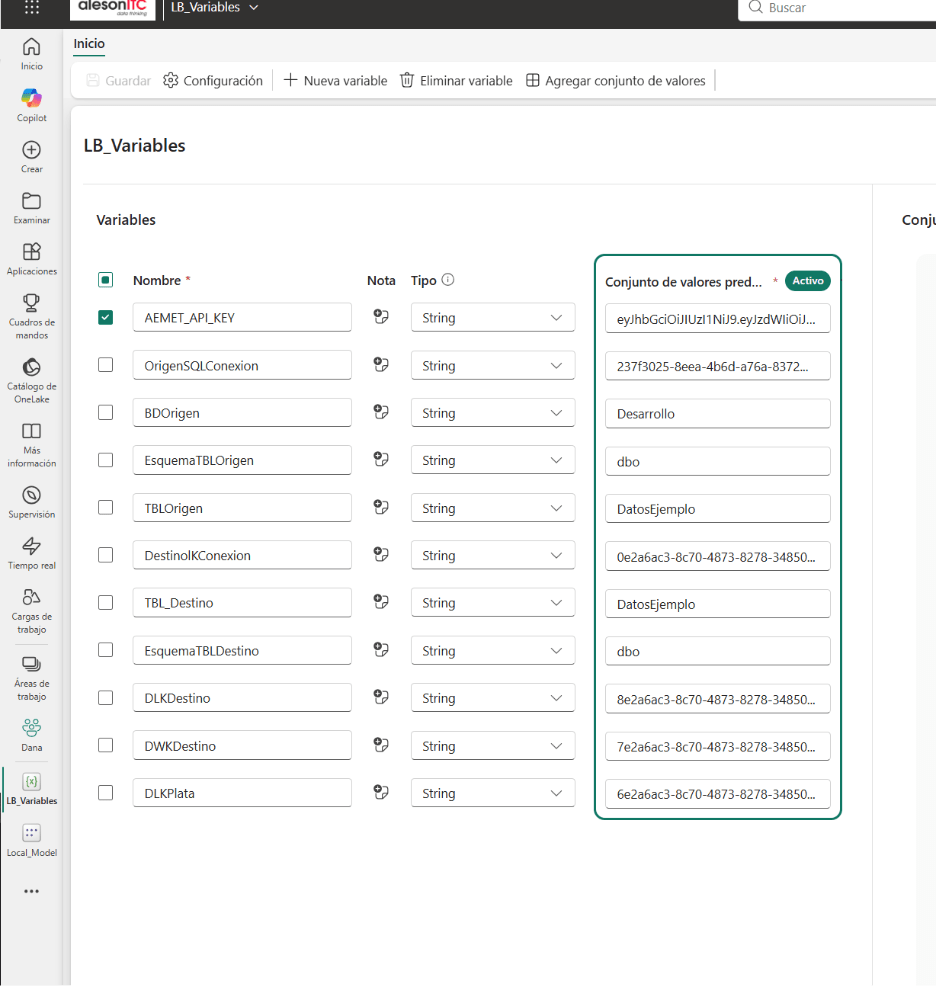
La base del enfoque es una librería de variables centralizada —denominada en este ejemplo LB_Variables— que actúa como fuente única de verdad para todos los parámetros del proyecto. En ella se almacenan:
- IDs de lakehouses, evitando que el notebook dependa de identificadores escritos directamente en el código.
- Conexiones a orígenes y destinos de datos, intercambiables por entorno sin modificar la lógica de procesamiento.
- Nombres de tablas y esquemas, estandarizando convenciones y reduciendo errores entre capas.
- APIs y parámetros técnicos: endpoints, rutas base, nombres de workspace o configuraciones específicas del proceso.
Este patrón aporta tres ventajas fundamentales:
- Separación de configuración y lógica: el notebook se centra en transformar datos, no en gestionar valores de infraestructura.
- Cambio de entorno sin tocar código: basta con ajustar los valores definidos en la Variable Library del entorno correspondiente.
- Gobernanza centralizada: facilita revisiones, auditoría y mantenimiento a medida que el proyecto crece.
Uso en el notebook
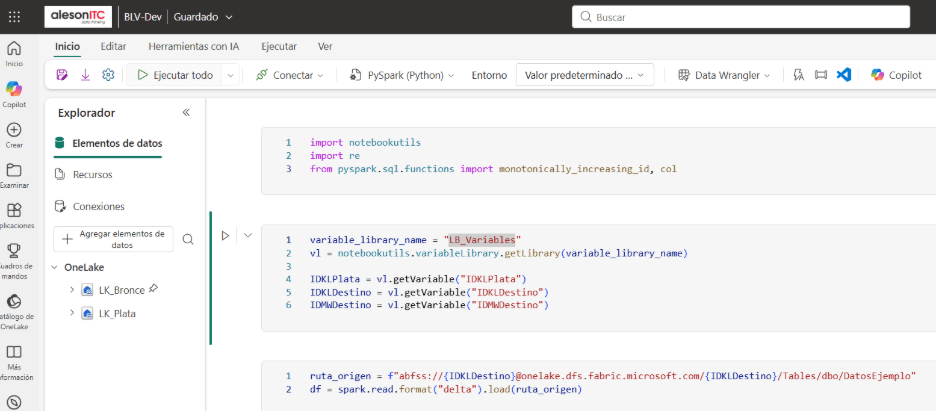
El notebook deja de depender de valores escritos en el código y pasa a leerlos desde la Variable Library. La variable variable_library_name define el nombre de la librería del proyecto; getLibrary la carga en memoria para su uso durante la ejecución. python
variable_library_name = "LB_Variables"
vl = notebookutils.variableLibrary.getLibrary(variable_library_name)
IDKLDestino = vl.getVariable("IDKLDestino")
Mediante getVariable("IDKLDestino") se recupera el identificador del lakehouse de destino. Este valor puede ser diferente en DEV, TEST o PROD, pero el notebook seguirá ejecutando exactamente la misma lógica. Al promocionar el artefacto entre entornos, solo cambia la configuración de la Variable Library, nunca el código del notebook.
La ventaja principal es que el notebook se vuelve más reutilizable, mantenible y seguro para despliegues multientorno, eliminando el riesgo de apuntar a un lakehouse incorrecto o de tener que modificar rutas e identificadores manualmente en cada despliegue.
2. Acceso dinámico a OneLake
A partir de las variables recuperadas, se construyen rutas dinámicas que resuelven en tiempo de ejecución el lakehouse o la tabla de destino correctos: python
ruta_origen = f"abfss://{IDKLDestino}@onelake.dfs.fabric.microsoft.com/{IDKLDestino}/Tables/dbo/DatosEjemplo"
Este patrón evita los problemas más habituales que genera el hardcoding de rutas:
- En Power BI, los cambios de rutas o nombres de tablas pueden romper modelos semánticos e informes ya publicados.
- En SQL, las consultas que dependen de nombres de esquema, tabla o capa de datos concretos se vuelven frágiles ante cualquier renombrado.
- En el modelado semántico, la consistencia en nombres y estructuras es crítica para mantener medidas, relaciones y documentación alineadas.
El mismo patrón es directamente aplicable a múltiples procesos de carga, transformación o validación, escalando el pipeline sin duplicar código ni lógica.
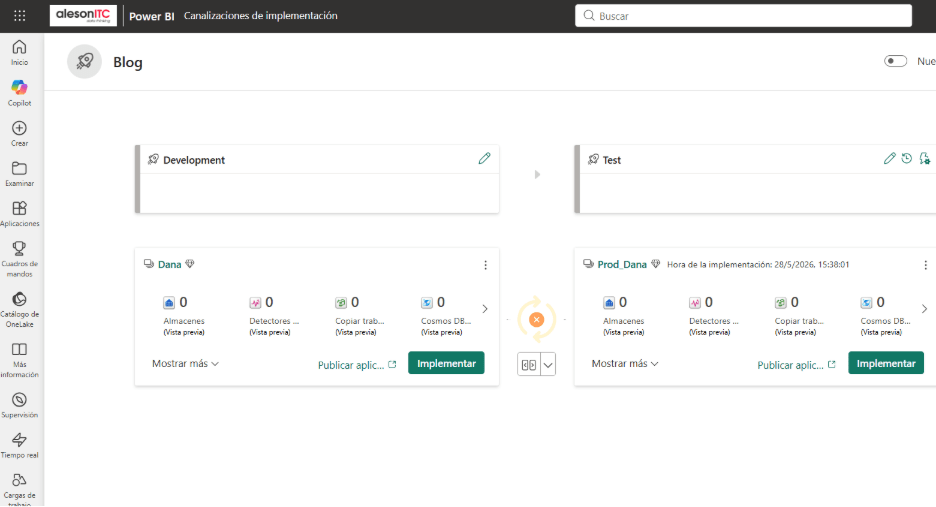
CI/CD con Deployment Pipelines
La solución se completa integrando Deployment Pipelines para gestionar el ciclo de vida completo de los artefactos:
- Development → Test → Production: flujo ordenado donde cada cambio se valida antes de alcanzar el entorno productivo.
- Promoción controlada de artefactos: evita mover notebooks, pipelines o lakehouses manualmente y sin trazabilidad.
- Separación real de entornos: configuraciones, permisos y datos diferenciados para reducir riesgos operativos.
El uso de variables es lo que hace que este flujo funcione de forma limpia:
- Cada entorno tiene sus propios valores, por lo que los artefactos apuntan a recursos distintos sin necesidad de duplicar notebooks ni pipelines.
- El código no cambia entre entornos, reduciendo el riesgo de introducir errores manuales durante el despliegue.
- El proceso de promoción es trazable y auditable, porque la lógica de negocio y la configuración están claramente separadas.
Buenas prácticas clave
- Centraliza variables desde el inicio para evitar refactorizaciones costosas cuando el proyecto ya tiene varios notebooks o pipelines en marcha.
- No hardcodees IDs ni rutas, especialmente en procesos destinados a desplegarse en varios entornos o reutilizarse por distintos equipos.
- Diseña notebooks pensando en multientorno: separa parámetros, lógica de negocio y validaciones desde el primer diseño.
- Integra ALM desde el principio para que la promoción entre entornos sea parte natural del ciclo de desarrollo y no una tarea manual de última hora.
¿Tu equipo trabaja con Microsoft Fabric en producción?
Gestionar correctamente las variables y los despliegues multientorno en Microsoft Fabric requiere tiempo de diseño y experiencia en patrones de ALM. Si tu equipo está escalando proyectos de datos en Fabric —o migrando desde Databricks, Azure Synapse o entornos on-premises— y necesita establecer una arquitectura sólida desde el principio, en Aleson ITC podemos ayudarte.
Como technology partner especializado en el ecosistema Microsoft, acompañamos a equipos de datos en el diseño, implementación y operación de soluciones sobre Microsoft Fabric, desde la ingesta hasta el modelado semántico y la entrega de informes en Power BI.
Nuestros servicios de Data Analytics y Microsoft Fabric cubren:
- Arquitectura de lakehouses y diseño de pipelines multientorno.
- Implementación de patrones de ALM con Deployment Pipelines.
- Migración y modernización desde plataformas de datos legacy.
- Formación y acompañamiento técnico para equipos internos.
Si tu proyecto está creciendo y la gestión de entornos empieza a ser un cuello de botella, habla con nuestro equipo. Evaluamos tu situación sin compromiso y te proponemos un camino concreto hacia una arquitectura de datos más robusta y mantenible.
FAQ — Preguntas frecuentes sobre gestión de variables en Microsoft Fabric
¿Qué es la Variable Library en Microsoft Fabric y para qué sirve?
La Variable Library es un componente de Microsoft Fabric que permite centralizar parámetros de configuración —como IDs de lakehouses, rutas, nombres de tablas o credenciales de conexión— fuera del código del notebook. Su principal utilidad es separar la configuración de la lógica de procesamiento, lo que facilita despliegues multientorno sin modificar el código entre DEV, TEST y PROD.
¿Cómo se accede a una Variable Library desde un notebook en Microsoft Fabric?
Se utiliza el objeto notebookutils.variableLibrary. Con getLibrary("nombre_libreria") se carga la librería, y con getVariable("nombre_variable") se recupera el valor de cada parámetro. Este patrón permite que el mismo notebook opere correctamente en distintos entornos simplemente cambiando la Variable Library configurada para cada uno.
¿Cómo se construyen rutas dinámicas a OneLake para evitar hardcodes?
A partir de los valores recuperados de la Variable Library, se construyen rutas abfss:// con f-strings de Python: f"abfss://{IDKLDestino}@onelake.dfs.fabric.microsoft.com/{IDKLDestino}/Tables/dbo/NombreTabla". Esto permite que la misma línea de código apunte al lakehouse correcto en cada entorno sin ninguna modificación manual.
¿Qué son los Deployment Pipelines en Microsoft Fabric y cómo se integran con las variables?
Los Deployment Pipelines son la herramienta de ALM nativa de Fabric para gestionar el ciclo de vida de los artefactos (notebooks, pipelines, lakehouses, modelos semánticos) entre entornos DEV, TEST y PROD. Cuando se combinan con una estrategia de Variable Library por entorno, la promoción de artefactos es completamente controlada: el código no cambia, solo se actualizan los valores de configuración del entorno destino.
¿Qué problemas evita parametrizar correctamente los notebooks en Microsoft Fabric?
Evita los errores más frecuentes en proyectos de datos: apuntar a un lakehouse incorrecto al promocionar entre entornos, duplicar notebooks para cada entorno, romper modelos semánticos de Power BI por cambios de rutas, y perder trazabilidad en los despliegues. Una buena parametrización hace el proyecto más seguro, mantenible y escalable a largo plazo.
¿Cuándo tiene sentido externalizar la arquitectura de datos en Microsoft Fabric?
Cuando el proyecto escala más allá de un equipo pequeño, cuando se gestiona más de un entorno de forma simultánea, o cuando la organización necesita garantías de calidad, gobernanza y continuidad.
En esos casos, contar con un partner especializado en Microsoft Fabric como Aleson ITC puede acelerar los tiempos de entrega y reducir el riesgo técnico del proyecto.

Business Intelligence Senior Consultant.