
Optimización de Tablas Delta en Fabric (Parte II): ZORDER, partitionBy y clusterBy

Optimizar tablas Delta en Microsoft Fabric pasa, inevitablemente, por elegir bien la estrategia de particionado. ZORDER, partitionBy y clusterBy son las tres herramientas principales que tienes a tu disposición, y cada una se comporta de forma muy diferente según el patrón de consulta de tu tabla.
En la primera parte analizamos la estructura de las tablas Delta y cómo afecta al rendimiento de las consultas. En esta segunda entrega vamos a ver en la práctica las distintas estrategias de particionado y ordenación disponibles: OPTIMIZE ZORDER, partitionBy y clusterBy, con tiempos de ejecución reales para que puedas comparar cuál se adapta mejor a tu caso de uso.
💡 Si aún no has leído la Parte 1, te recomendamos hacerlo antes de continuar: sienta las bases necesarias para entender los resultados de esta entrada.
1. OPTIMIZE ZORDER
OPTIMIZE ZORDER combina dos operaciones en un único comando:
- OPTIMIZE compacta los archivos pequeños. Si tienes, por ejemplo, 10 archivos de 10 MB, los reescribirá en un único archivo de 100 MB.
- ZORDER ordena los datos dentro de esos archivos compactados por la columna que especifiques, de forma que los valores relacionados queden físicamente próximos en el almacenamiento.

Al lanzar el comando nos devuelve la siguiente información:

En el ejemplo de prueba, la ejecución eliminó los 16 archivos Parquet originales y los compactó en 1 solo archivo, aplicando el ZORDER sobre él.
Resultado sobre la query de test
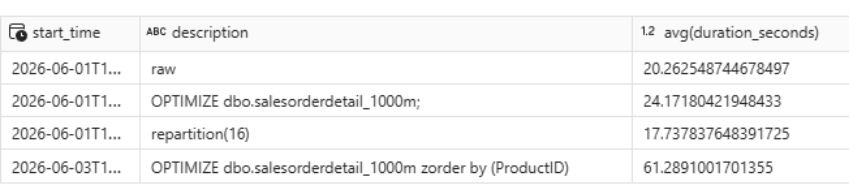
El tiempo de ejecución empeoró de 17,73 s a 61,28 s. Esto ocurre porque la query filtraba por ProductID en la tabla Product, no en salesorderdetail_1000m, que es la tabla sobre la que se aplicó el ZORDER. La ordenación no está ayudando en la tabla y la columna del filtro.
Para comprobarlo, modificamos la consulta para que el filtro por ProductID recaiga directamente sobre salesorderdetail_1000m:
SELECT p.name AS Product, COUNT(*) AS Sales, COUNT(DISTINCT SalesOrderID) AS DiffSales, SUM(LineTotal) AS Total FROM dbo.salesorderdetail_1000m AS a JOIN dbo.Product AS p ON p.ProductID = a.ProductID WHERE a.ProductID IN (955, 748, 935) GROUP BY p.name;

Con este ajuste se obtiene una mejora de 5 segundos, aunque no llega al nivel del repartition(16) visto en la parte anterior. La conclusión es clara: ZORDER solo es efectivo cuando la columna ordenada coincide con la tabla y la columna del filtro activo.
2. partitionBy
partitionBy particiona la tabla por las columnas indicadas, creando un archivo Parquet independiente para cada valor distinto de esa columna. Es el equivalente en Delta al particionado clásico de Hive.
df = spark.read.table("demo_rendimiento_delta.dbo.salesorderdetail_1000m")
df.write
.format("delta")
.mode("overwrite")
.option("overwriteSchema", "true")
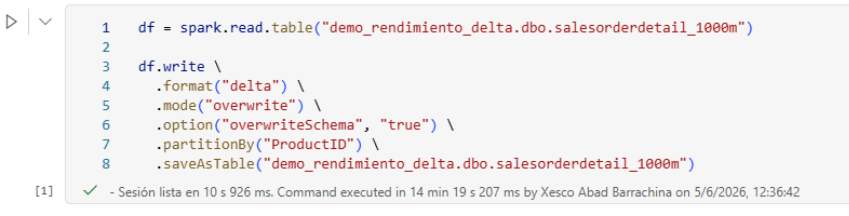
.partitionBy("ProductID")
.saveAsTable("demo_rendimiento_delta.dbo.salesorderdetail_1000m")
Después de la escritura, lanzamos DESCRIBE DETAIL para revisar el estado de la tabla:
DESCRIBE DETAIL demo_rendimiento_delta.dbo.salesorderdetail_1000m;
| Propiedad | Valor |
|---|---|
partitionColumns | ["ProductID"] |
clusteringColumns | [] |
numFiles | 142 |
sizeInBytes | 81.376.866 |
Ahora la tabla tiene 142 particiones, una por cada ProductID distinto.
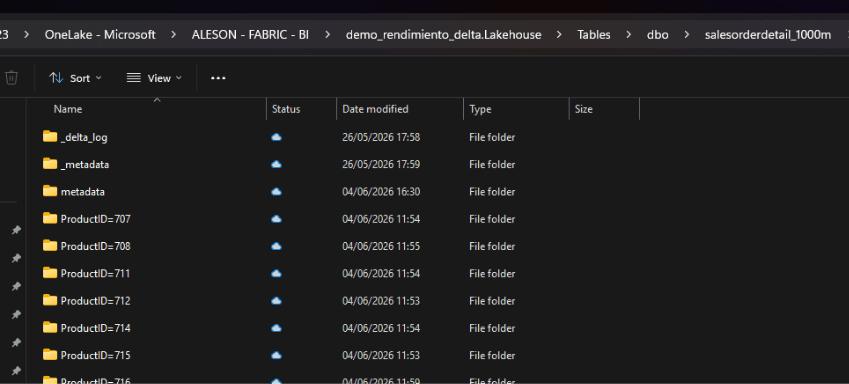
Explorar las particiones en OneLake
Puedes verificar la estructura física abriendo Microsoft OneLake File Explorer for Windows (descarga aquí), navegando hasta tu Lakehouse y accediendo a la carpeta de la tabla. Verás una subcarpeta por cada valor de ProductID.
Resultado sobre la query de test
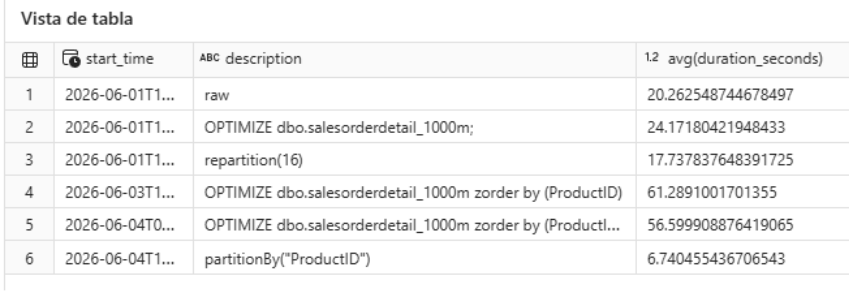
El tiempo de ejecución pasó de 20,26 s a 6,74 s, una mejora de aproximadamente el 300%. La razón es directa: como la query filtra por solo 3 valores de ProductID, el motor solo tiene que leer 3 de las 142 particiones, ignorando el resto por completo (partition pruning).
⚠️ Precaución con la cardinalidad. Si en lugar de 142 valores distintos tuviéramos decenas de miles, el particionado generaría una fragmentación excesiva que perjudicaría al rendimiento en consultas que no filtren por
ProductID. Este problema se trata en detalle en la Parte 1.
3. clusterBy
clusterBy es la alternativa moderna al particionado clásico. En lugar de crear directorios físicos por valor de columna, aplica una ordenación inteligente dentro de cada archivo para que los registros con valores próximos de la columna indicada queden agrupados. No es compatible con partitionBy en la misma tabla.
CREATE OR REPLACE TABLE dbo.salesorderdetail_1000m USING DELTA CLUSTER BY (ProductID) AS SELECT * FROM dbo.salesorderdetail_1000m;
El resultado de DESCRIBE DETAIL tras la operación:
| Propiedad | Valor |
|---|---|
partitionColumns | [] |
clusteringColumns | ["ProductID"] |
numFiles | 8 |
sizeInBytes | 84.835.802 |
La tabla pasa a tener 8 archivos, ordenados internamente por ProductID. Es una opción sólida y con menos riesgo de fragmentación que partitionBy, aunque para esta query concreta sigue siendo inferior: al filtrar por solo 3 valores de ProductID, partitionBy permite ignorar 139 particiones de golpe, mientras que clusterBy tiene que escanear los 8 archivos aunque de forma más eficiente.
4. PARTITIONED BY + ZORDER BY
Esta es la única combinación que Delta permite: particionar por una columna y aplicar ZORDER dentro de cada partición por una columna diferente. En nuestro caso, particionamos por ProductID y ordenamos cada partición por SalesOrderID, dado que la query incluye un COUNT(DISTINCT SalesOrderID).
Paso 1 — Ejecutar partitionBy:
Paso 2 — Ejecutar OPTIMIZE ZORDER:

Nota:
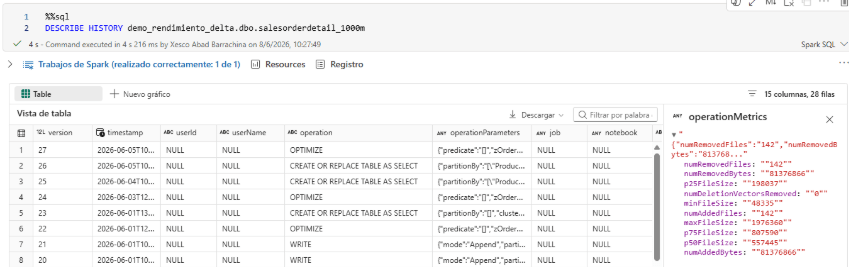
DESCRIBE DETAILno refleja la información deZORDER. Para consultarla, usa el log de la tabla:
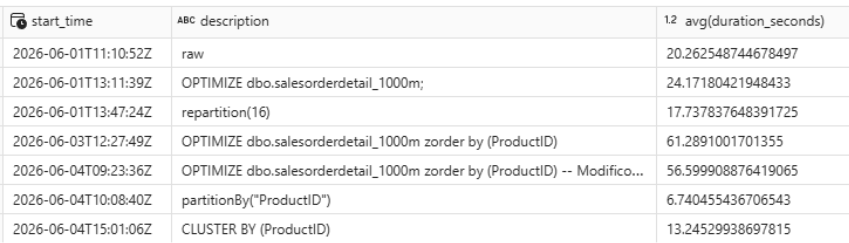
DESCRIBE HISTORY demo_rendimiento_delta.dbo.salesorderdetail_1000m;

Historial transaccional de una tabla Delta
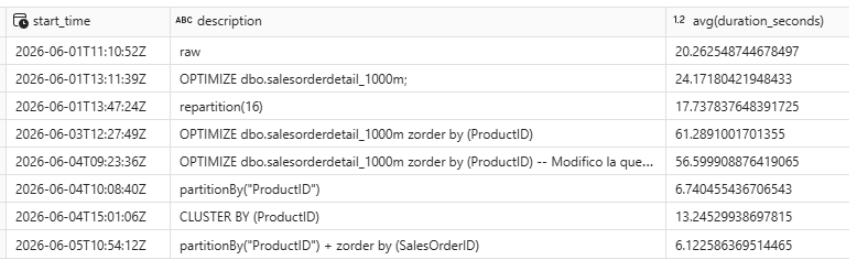
La combinación partitionBy + ZORDER BY registra una leve mejora sobre la mejor marca anterior, aunque la diferencia no es dramática para esta query en particular.
Conclusión
Al igual que ocurre en las bases de datos relacionales, no existe una configuración óptima universal para las tablas Delta. La estrategia correcta depende completamente del patrón de uso:
OPTIMIZE ZORDERes útil cuando quieres compactar archivos y hay un patrón de filtrado claro, pero no crea particiones físicas. Solo beneficia las queries que filtran por la columna ordenada.partitionByofrece el mayor salto de rendimiento cuando la cardinalidad de la columna es baja y los filtros siempre incluyen esa columna. Con alta cardinalidad genera fragmentación.clusterByes la opción más flexible y con menor riesgo de fragmentación. Recomendable cuando el patrón de acceso es variado o la cardinalidad es alta.partitionBy + ZORDER BYcombina la velocidad del particionado con una ordenación interna de segundo nivel. Apropiada cuando hay dos dimensiones de filtrado relevantes.
Un Data Warehouse destinado a alimentar un modelo semántico tiene patrones de acceso completamente distintos a los de una tabla operacional consultada por una aplicación. Define primero el caso de uso y luego elige la estrategia.
FAQ — Preguntas frecuentes sobre particionado en tablas Delta y Microsoft Fabric
¿Cuándo debo usar partitionBy y cuándo clusterBy en una tabla Delta?
Usa partitionBy cuando la columna de partición tenga baja cardinalidad (pocas decenas o centenas de valores distintos) y tus queries casi siempre filtren por ella. Usa clusterBy (Liquid Clustering) cuando la cardinalidad sea alta o el patrón de acceso sea variado: evita la fragmentación y no requiere mantenimiento manual. En Microsoft Fabric, Databricks recomienda clusterBy como opción por defecto para tablas nuevas.
¿Qué hace exactamente OPTIMIZE ZORDER en Delta Lake?
OPTIMIZE compacta los archivos Parquet pequeños en archivos más grandes para reducir el número de operaciones de I/O. ZORDER reordena los datos dentro de esos archivos de forma que los registros con valores próximos en la columna indicada queden físicamente juntos. El resultado es que el motor puede saltar bloques irrelevantes durante la lectura (data skipping). Solo mejora el rendimiento si la query filtra por la columna que se usó en ZORDER.
¿Por qué DESCRIBE DETAIL no muestra información de ZORDER?
ZORDER es una operación de reordenación física, no un metadato estructural de la tabla. Delta Lake no la almacena como propiedad en DESCRIBE DETAIL. Para ver el historial completo de operaciones —incluyendo OPTIMIZE ZORDER— debes consultar DESCRIBE HISTORY nombre_tabla, que registra cada operación aplicada con su timestamp y parámetros.
¿Puedo combinar partitionBy y clusterBy en la misma tabla Delta?
No. Delta Lake no permite usar ambas estrategias simultáneamente en la misma tabla. Sí puedes combinar partitionBy con ZORDER BY: primero particionas la tabla y luego ejecutas OPTIMIZE ZORDER para ordenar dentro de cada partición por una segunda columna. Es la única combinación de dos niveles de ordenación soportada de forma nativa.
¿Cómo afecta el particionado en Delta al rendimiento de un modelo semántico en Power BI o Microsoft Fabric?
El impacto depende del patrón de acceso del modelo. Si el modelo semántico lanza queries que filtran por la columna de partición, el beneficio es directo y significativo. Si las queries agregan sobre toda la tabla sin filtros selectivos, el particionado aporta poco y puede incluso incrementar el tiempo de carga por la fragmentación. Lo ideal es diseñar la estrategia de particionado alineada con los filtros más frecuentes de los informes. Si necesitas ayuda para optimizar esta capa, el equipo de Data Analytics de Aleson ITC puede hacer una revisión de tu arquitectura.
¿Qué estrategia de particionado recomienda Databricks/Microsoft Fabric para tablas grandes en producción?
La recomendación actual de Databricks para Delta Lake en Microsoft Fabric es usar Liquid Clustering (clusterBy) en lugar de partitionBy para tablas nuevas, especialmente cuando superen los 200 GB o tengan patrones de acceso variables. Liquid Clustering permite reorganizar los datos incrementalmente con OPTIMIZE sin necesidad de reescribir la tabla completa, lo que reduce drásticamente los costes de mantenimiento en producción.
Business Intelligence Expert Consultant. Specialising in creation of Data Warehouse, Fabric, Analysis Services, Databricks, Power BI, SSIS and SSRS.
