
Machine Learning 2.0 – Análisis Exploratorio de Datos
En el post de hoy vamos a hablar del Análisis Exploratorio de los Datos utilizando la librería Pandas en Azure Synapse Analytics, uno de los pasos más importes a la hora de empezar un proyecto de Machine Learning.
El Análisis Exploratorio de Datos (Exploratory Data Analysis) consiste en una de las primeras tareas que tiene que desempeñar el Científico de Datos, la cual consiste en comprender los datos que nos llegan y tratar de identificar posibles patrones que puedan ser útiles para lograr conseguir el objetivo que se nos propone.
Pasos de la Tarea
- ¿Cuántos registros hay? ¿Son demasiado pocos? ¿Son muchos y no tenemos Capacidad suficiente para procesarlo?
- ¿Están todas las filas completas ó tenemos campos con valores nulos? En caso que haya demasiados nulos: ¿Queda el resto de información inútil? O ¿lo sustituímos por el valor más repetido? Por ejemplo.
- ¿Qué datos son discretos y cuáles continuos?
- ¿Están los datos normalizados? ¿Tenemos suficientes muestras de cada clase y variedad?
- Si es un problema de tipo supervisado:¿Cuál es la columna de “salida”? ¿binaria, multiclase?¿Está balanceado el conjunto salida?
- ¿Qué características son importantes? ¿Cuáles podemos descartar?¿Siguen alguna distribución? ¿Hay correlación entre las características que estamos estudiando?
- ¿Estamos ante un problema dependiente del tiempo?
- ¿Cuáles son los Outliers? ¿Son errores de carga o son reales?
CASO EJEMPLO
Para poder realizar todas estas tareas, Python nos proporciona la librería Pandas que nos ayuda con la manipulación de los datos, a poder leerlos, entenderlos y transformarlos. Veamos un ejemplo práctico de todo esto utilizando Azure Synapse Analytics:
“Los taxistas de Nueva york quieren reducir su jornada laboral pero quieren aprovechar al máximo las horas de trabajo, es decir, quieren salir a trabajar en la franja horaria dónde la probabilidad de recibir propina sea mayor.“
Para ello, cogemos los conjuntos de datos de los registros de viaje en taxi de Nueva York que incluyen los siguientes campos: fechas / horas de recogida y devolución, lugares de recogida y devolución, distancias de viaje, tarifas detalladas, tipos de tarifas, tipos de pago y recuentos de pasajeros informados por el conductor y cantidad de propina.
Además, vamos a coger la información meteorológica para juntarla con la de los registros de los taxis ya que creemos que puede ser de vital importancia ya que el tiempo puede ser una claro condicionante en la decisión del cliente a la hora de coger taxi y dejar propina.
Veamos como manejar estos datos desde Synapse:
import pandas as pd
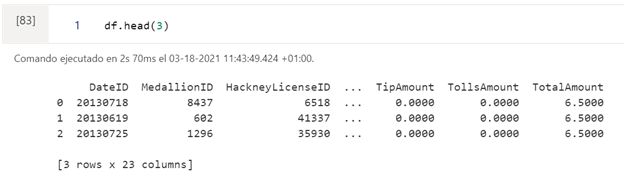
Primero transformamos nuestra tabla de SQL en un dataframe de Pandas y mostramos la cabecera.

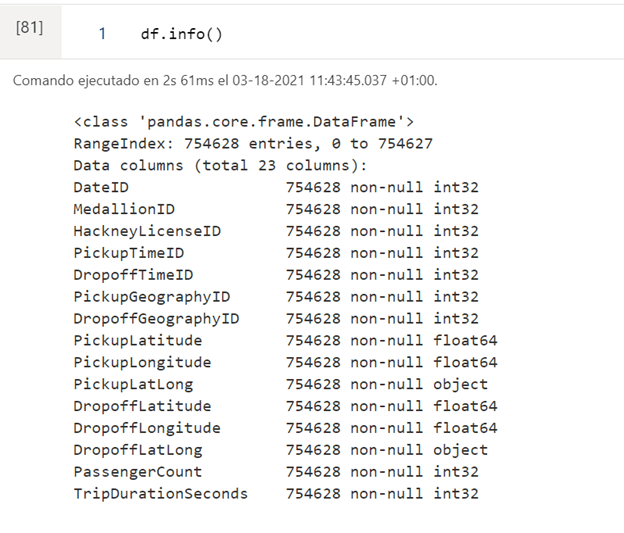
En la siguiente salida vemos los nombres de las columnas, el total de filas y la cantidad de filas sin nulos. También los tipos de datos.
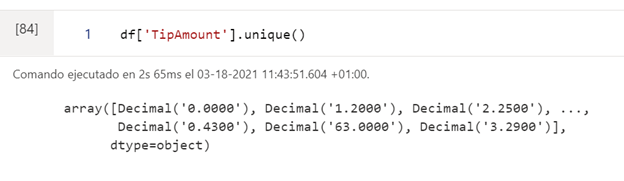
La librería pandas tiene funciones predefinidas, como en este caso unique(), que nos permite ver los posibles valores que puede tomar una columna (característica) en concreto:
También podemos tratar este tipo de datos con consultas SQL:

Tenemos funciones en la librería Pandas que nos permiten seleccionar ciertos campos de una fecha completa, sumar, ordenar y agrupar.

Además, podemos definir otras funciones que nos ayuden a analizar nuestros datos:

Y, por supuesto, filtrarlos:

Podemos también transformar los datos categóricos a numéricos con la función LabelEcncoder(), esta es una función muy importante para poder aplicar Machine Learning.

Que, por ejemplo, en este caso está cambiando los atributos ‘AMRush’ por 0 y ‘Afternoon’ por 1, de esta forma ahora si podemos aplicar un algoritmo de predicción, como en este caso aplicamos la regresión logística, ya que solo trabaja con columnas numéricas.
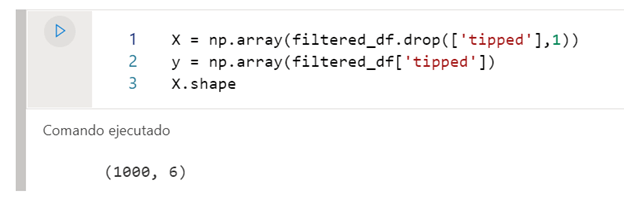
Para elaborar el modelo, le pasaremos por un lado las características con las que tiene que entrenar el modelo, y por otro, las etiquetas que tiene que tiene que tratar de predecir.
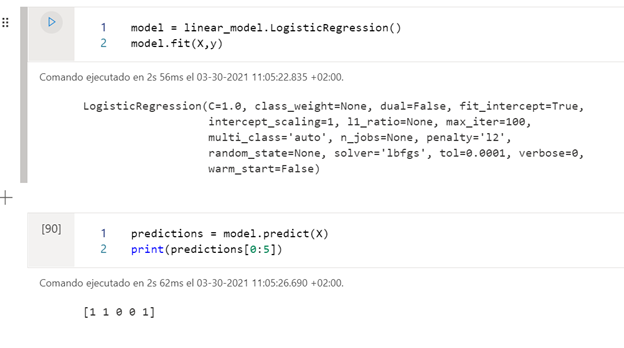
En este caso, una vez hemos entrenado el modelo, mostramos las predicción de si recibirán propina o no con el modelo de Machine Learning que hemos creado. Es mejor antes de entrenar el modelo separar todo el conjunto de datos en conjunto de entrenamiento y conjunto de test, para no sobreentrenar el conjunto.
Y hasta aquí el post de hoy, si estas interesado en las últimas tecnologías y estas aprendiendo Machine Learning, no te pierdas este post para principiantes en Inteligencia Artificial.
Si quieres que ayudemos a tu negocio o empresa contacta con nosotros en info@aleson-itc.com o llámanos al +34 962 681 242

Business Intelligence Senior Consultant.