
Conoce las estadísticas de espera o Waits para SQL Server

Bienvenidos a un nuevo post en el mejor Blog de SQL Server. En la entrada de hoy vamos a hablar sobre una de las herramientas mejor valoradas a la hora de crear estadísticas de espera en SQL Server: los Waits.
Pero primero, os explicaré qué son los Waits y cuáles son sus principales funciones.
¿Qué son los Waits?
Las estadísticas de espera de SQL Server son una herramienta importante que se utiliza para analizar problemas relacionados con el rendimiento o para optimizar el rendimiento de SQL Server. Los tiempos de espera son capturados y registrados por SQL Server y toda esa información capturada se llama estadísticas de espera y brinda asistencia para resolver problemas relacionados con el rendimiento de SQL Server.
Para saber que tipos de esperas tenemos en la Instancia, usaremos el siguiente Script:
Ref: Consulta de query https://www.sqlskills.com/blogs/paul/wait-statistics-or-please-tell-me-where-it-hurts/
IMPORTANTE
Las estadísticas de espera, son uno de los indicadores más importantes para identificar problemas de rendimiento en SQL Server. Cuando queramos solucionar cualquier problema de rendimiento, primero debemos de diagnosticar el problema correctamente, para ello, vamos a identificar las principales WAITS que pueden salirnos y cómo solucionar el problema.
TIPOS DE WAITS EN SQL SERVER
Ref: https://www.sqlshack.com/sql-server-wait-types/
Tipos de WAITS más comunes y su solución:
1º CXPACKET:
Nos indica que muchas consultas de ejecución se están paralelizando. Esto no tiene porqué ser MALO, pero consume recursos adicionales de CPU, si la utilización del procesador en la Instancia por lo GENERAL es superior al 80%, deberíamos investigar.
Solución
- Examina las consultas que más CPU consumen para ver si se pueden Optimizar o nos piden algún Missing Index. Estas consultas son claras candidatas a optimizarse mediante la revisión de su código o la creación de índices faltantes, ya que con ello conseguiremos que el rendimiento total del servidor mejore.
Os dejo enlace para más información: https://learn.microsoft.com/en-us/troubleshoot/sql/performance/troubleshoot-high-cpu-usage-issues
- Configurar de manera correcta el MAXDOP y paralelismo: Debemos de revisar si los valores de Grado de Paralelismo Máximo y Umbral de costo para el paralelismo son los más idóneos, una rápida explicación de paralelismo sería el número máximo de cores que una consulta podrá utilizar.
Os dejo enlace para más información: https://learn.microsoft.com/en-us/sql/database-engine/configure-windows/configure-the-max-degree-of-parallelism-server-configuration-option?view=sql-server-ver16#recommendations
2º BACKUPIO:
Esto se produce cuando una tarea de copia de seguridad está esperando datos o está esperando un búfer en el que almacenar datos. Este tipo no es típico, excepto cuando una tarea está esperando un montaje en cinta. Tened en cuenta que todas las esperas de copia de seguridad también se acumulan para las operaciones de restauración.
Solución
- Activar el backup compress si está disponible en la versión.
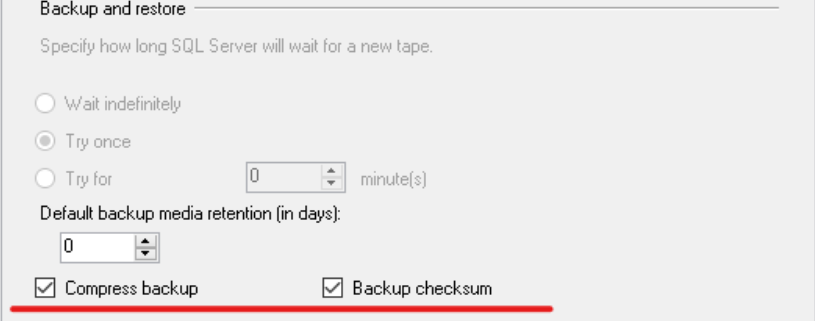
- Eliminar los índices no utilizados ( menos datos para respaldar) SIEMPRE CUIDADO CON ESTO Y ASEGURARSE DE QUE NO ES DE APLICATIVO.
3º SOS_SCHEDULER_YIELD
Las instancias de SQL Server con un alto uso de CPU a menudo muestran el tipo de espera SOS_SCHEDULER_YIELD. Esto no significa que el servidor tenga poca potencia; significa que se necesita más investigación para encontrar qué tarea individual en una consulta necesita más tiempo de CPU.
Solución:
- Examina las consultas que más consumen CPU para ver si se pueden Optimizar o nos piden algún Missing Index, para ello usaremos el anterior enlace proporcionado.
- También podemos encontrar en el siguiente DMV (Dynamic Management Views) cuántos recuentos de tareas ejecutables hay en el sistema. Si observamos un número de dos dígitos en runnable_tasks_count continuamente durante mucho tiempo ( no de vez en cuando) sabrá que hay presión de la CPU. El número de dos dígitos generalmente se considera algo malo.
DMV recuento de tareas ejecutables
SELECT scheduler_id, current_tasks_count, runnable_tasks_count, work_queue_count, pending_disk_io_countFROM sys.dm_os_schedulersWHERE scheduler_id < 255GO |
4º ASYNC_NETWORK_IO:
Aquí no hay nada que pueda hacerse para ajustar el rendimiento de SQL Server. Ya que lo más común es que podría ser una tubería de red entre la aplicación y el servidor de SQL Server ( como una red de área amplia de larga distancia), una máquina cliente con poca potencia o un procesamiento fila por fila que ocurre en el servidor de aplicaciones.
Solución:
- Aunque anteriormente hemos dicho que como DBAS no podemos hacer mucho, SÍ que podemos dar valor añadido al cliente y proporcionarles información, lo que podemos hacer para ayudar a los desarrolladores a delimitar lo que sucede, es ejecutar sp_WhoIsActive varias veces. Busque consultas que están esperando en ASYNC_NETWORK_IO, vea qué consultas son y de qué máquinas provienen. Es posible que vea un patrón de solo un par de consultas.
5º WRITELOG:
Está nos indica que SQL Server está esperando que completen las escrituras en el disco de LOG. Si el valor es alto, podría indicar un cuello de botella en el disco de LOG.
Solución:
- Deshabilitar los índices no utilizados. Esto disminuirá el número de escrituras durante las modificaciones de datos. SIEMPRE CUIDADO CON ESTO Y ASEGURARSE DE QUE NO ES DE APLICATIVO.
- Asegurarse del FILL FACTOR que esté bien configurado para evitar divisiones de página: El Fill Factor nos indica que porcentaje de tamaño del índice se dejará libre cuando se haga una operación de REBUILD. Esta opción es una BEST PRACTICES porque dejando espacio libre suficiente para el crecimiento interno del índice, conseguiremos que todas las páginas estén localizadas en el mismo sector del disco con lo que evitaremos fragmentación.
6º PAGEIOLATCH_SH:
Este tipo de espera se acumula mientras SQL Server espera que se recupere una página del disco y se cargue en la memoria. La página recopilada se utilizará para un propósito ( operación de lectura). Si este valor es alto, es probable que el disco o la memoria disponible no estén a la altura de la carga de trabajo.
Solución:
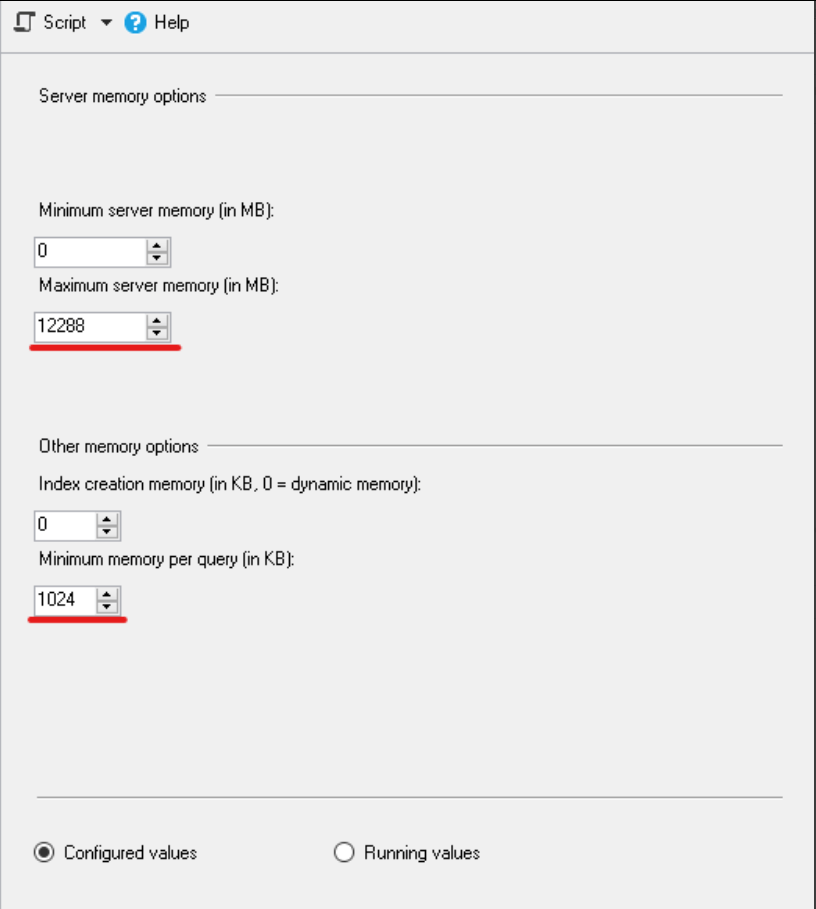
- Aumentar la asignación máxima de memoria: Actualmente en las versiones nuevas de SQL Server, ya nos recomienda el Max Server Memory, pero sí no es así, la manera que lo calcularemos es RAM menos los Cores multiplicado por 1024.
Otra herramienta útil para calcular esto es: https://sqlmax.chuvash.eu/
- Investigar las latencias de Disco: La latencia de disco nos proporciona información de lecturas y escrituras a discos relacionados con SQL Server.
Os dejo enlace para más información: https://theserogroup.com/dba/identifying-sql-server-disk-latency/
- Indexación, busca consultas de I/O de disco altas, examine las consultas que más consumen CPU para ver si se pueden Optimizar o nos piden algún Missing Index. Utiliza el enlace anteriormente proporcionado.
- Asegurarse de que las tablas de esas BBDD están comprimidas, ya que los datos comprimidos viajarán por la red más rápido, además el tamaño que ocupa la BBDD en disco se verá reducido y las tareas de backup o de mantenimiento se realizarán considerablemente más rápido.
Os dejo enlace para más información: https://sqlstarters.com/2017/03/28/sql-server-data-compression/
- Como último recurso, agregar memoria adicional.
7º LCK_M_S:
Esta espera ocurre cuando una solicitud está esperando para adquirir un bloqueo compartido. Esto suele ocurrir cuando las solicitudes de lectura se bloquean mediante transacciones de escritura (implícitas o explicitas) que se han mantenido abiertas durante largos periodos de tiempo.
Solución:
- Investigue la posibilidad de poner a nivel de BBDD la configuración READ_COMMITEDD_SNAPSHOT.
- Examine las consultas que más consumen CPU para ver si se pueden Optimizar o nos piden algún Missing Index. Utiliza el enlace anteriormente proporcionado.
8º OLEDB:
Es común ver este tipo de espera en instancias que alojan servidores vinculados. OLEDB también se usa en Bulk Insert, el motor de texto completo y dentro de SQL Server Management Studio.
Solución:
- Asegúrate de que los Linked Servers estén configurados con las Best Practices.
Os dejo enlace para más información: https://www.sqlshack.com/how-to-create-and-configure-a-linked-server-in-sql-server-management-studio/
- Optimice las consultas que se ejecutan en los Linked Servers.
- Mantén las transacciones sobre los Linked Servers lo más breve posible.
- Para la carga masiva, asegúrese de que los archivos se coloquen en un almacenamiento rápido.
9º BACKUPTHREAD:
Esta espera por lo general, ocurre mientras se espera que se complete alguna I/O en un subproceso, como la inicialización cero de un archivo de datos o de registro. Tened en cuenta, que todas las esperas de copia de seguridad también se acumulan para las operaciones de restauración.
Solución:
- Habilite realizar tareas de mantenimiento de volumen para evitar la inicialización cero de los archivos de datos.
- Mire la configuración de los crecimientos de las BBDD y asegúrate que el crecimiento sea automático en un número fijo de megabytes en lugar de %.
10º RESOURCE_SEMAPHORE:
Esto ocurre, cuando las solicitudes de memoria de consultas no se pueden otorgar debido a otras consultas simultáneas. Los valores altos de este tipo de espera pueden indicar un número excesivo de consultas simultáneas o solicitudes de memoria excesivas.
Solución:
- Asegurarse de que las estadísticas estén actualizadas. Tened en cuenta que las estadísticas son uno de los elementos más importantes que ayudan al desempeño de los servidores de SQL Server. Las estadísticas son la principal fuente de información para que se usa el optimizador de consultas para tomar decisiones de cómo resolver una consulta. Con las estadísticas el optimizador puede estimar la selectividad de los predicados y así tomar decisiones sobre cuando usar un índice o no.
- Ejecutar el siguiente script para saber que consultas requieren una cantidad excesiva de memoria:
Consultas que usan más memoria
EXEC dbo.sp_BlitzCache @SortOrder = 'memory grant' |
- Asegúrate que el MAX Server Memory esté bien configurado.
- Por último, si todo es correcto deberemos asignar más memoria al SQL Server, ya que nos indica presión de memoria.
11º LCK_M_U:
Esta espera ocurre mientras una solicitud está esperando para adquirir un bloqueo de actualización. Un bloqueo de actualización no es solo para operaciones de ACTUALIZACIÓN. Se usan cuando SQL Server necesita leer y luego modificar una fila/ página/tabla. Antes de las modificaciones, colocará un bloqueo de actualización en los datos. Una vez que el sistema esté listo, estos bloqueos se actualizarán a bloqueos exclusivos. Esta espera generalmente ocurre mientras las solicitudes de modificación están bloqueadas por otras transacciones de escritura (implícitas o explícitas).
Solución:
- Mantenga cortas las duraciones de las transacciones o ver transacciones que estén en sleeping.
- Asegurarse de que los niveles de aislamiento de las transacciones sean apropiadas (evite SERIALIZABLE y REPEATABLE READ si es posible)
- Habilitar si es posible la configuración de las BBDD en READ_COMMITED_SNAPSHOT.
- Investigar consultas por falta de indexación.
Y hasta aqui el post de hoy, si te ha sido de ayuda, te recomendamos los siguientes posts de SQL Server:
Aprendiendo a organizar SQL Server Management Studio para distintos entornos
¿Estas en SQL Server 2012? Es el momento de migrar
Si tienes problemas de rendimiento con tu SQL Server, te recomendamos nuestro servicio de SQL Server Health Chek.

Project Manager at Aleson ITC, Passionate about constantly developing my skills and growing professionally, I love technology and analysing big data to make strategic decisions.