
Ledger para SQL Server 2022

¡Hola! Bienvenidos/as a un nuevo post en el mejor blog de Data y Cloud. En el arículo de hoy vamos a hablar de Ledger para SQL Server 2022. ¡Empezamos!
Introducción
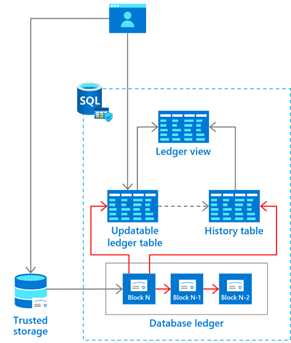
Con la llegada de la versión 2022 de SQL Server, Microsoft ha introducido un sistema seguro a prueba de manipulaciones que garantiza la integridad de los datos. Ledger se basa en blockchain para garantizar que no se puedan realizar cambios sin que sean visibles. Para los que aún no se sepan la naturaleza del blockchain en 2023, básicamente es una cadena de bloques o testigos que contienen información codificada de una transacción. Estos testigos, al estar entrelazados, permite la transferencia de datos codificados de manera segura a través de la criptografía. Esto hace que, una vez que se introduce información, no se puede eliminar, puesto que se tendrían que modificar la información de los testigos anteriores.
Otras tecnologías de SQL Server que proporcionan acceso a un histórico de cambios, como el CDC (Change Data Capture), no son a prueba de manipulaciones, puesto que los usuarios privilegiados pueden manipular los datos. La tecnología blockchain hace que dicha manipulación sea imposible, ya que cualquier cambio se guarda encriptado y contiene el bloque previo también encriptado.
En entornos donde la integridad de los datos almacenados es clave (como organizaciones con datos financieros, médicos o datos confidenciales), establecer la confianza en torno a la integridad ha sido un problema persistente a lo largo del tiempo. La nueva característica de SQL Server 2022 ayuda a proteger los datos de cualquier fuente, ya sea un atacante, usuario con privilegios elevados, administradores de bases de datos del sistema y de la nube.
Los datos históricos se administran de manera transparente a las aplicaciones, de forma que no se tiene que realizar ningún cambio. Dichos datos tienen un formato relacional, de manera que admiten consultas SQL con fines de auditoría o análisis forense. Gracias a esto, además de garantizar la integridad de los datos también aprovecha la eficacia, flexibilidad y rendimiento de las bases de datos SQL.
Casos de uso
Auditorías
Es quizás el primer caso de uso que se nos viene a la cabeza a la hora de implementar Ledger.
En cualquier sistema productivo, es necesario confiar en los datos que se consumen y producen. Si los datos han sido alterados malintencionadamente, puede resultar en desastre en los diferentes procesos empresariales que dependen de esos datos.
Una auditoría verifica que los procesos implementados sea correctos, revisa los registros de auditoría e inspecciona los controles de autenticación y acceso. Estos procesos manuales pueden sacar a la luz posibles fallos en la seguridad del sistema, pero no pueden proporcionar una prueba verificable de que los datos no se han modificado de forma malintencionada.
Ledger demuestra la integridad de los datos de forma criptográfica. Esta prueba ayuda a simplificar el proceso de auditoría.
Confiabilidad de los datos
En ocasiones, es necesario compartir cierta información entre las diferentes cadenas de suministro de una empresa. Esto es un reto cuando necesitas compartir datos y confiar en ellos al mismo tiempo.
La tecnología blockchain implementada con Ledger es la solución perfecta para cuando necesitamos corroborar la integridad de los datos de forma centralizada en redes donde la confianza es baja.
Almacenamiento fuera de la blockchain
Cuando una red blockchain es necesario para algún proceso corporativo, es necesario poder consultar los datos sin sacrificar el rendimiento general del sistema.
La solución que se suele utilizar para resolver este problema es replicar los datos de la blockchain a un almacén, como una base de datos SQL. Ledger garantiza la integridad de los datos para el almacenamiento fuera de la blockchain, lo que garantiza la confianza en los datos en todo el sistema.
Ejemplo práctico
USE master; GO -- Creamos la base de datos de prueba -- DROP DATABASE IF EXISTS DB_Ledger; GO CREATE DATABASE DB_Ledger; GO USE DB_Ledger; GO -- Activamos el SNAPSHOT ISOLATION para poder verificar el Ledger ALTER DATABASE DB_Ledger SET ALLOW_SNAPSHOT_ISOLATION ON; GO
Con el Snapshot Isolation activado, nos aseguramos que las transacciones que realicemos en el servidor estén aisladas unas de otras, formando bloques de transacciones. Después veremos la utilidad de esto.
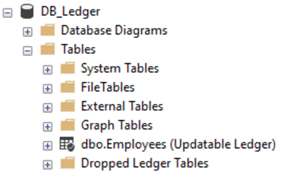
USE DB_Ledger; GO /* Creamos la tabla ejemplo Employees y la marcamos como tabla Ledger. Nota : De momento, todavía no se puede actualizar una tabla para añadir la funcionalidad del Ledger, solo a la hora de crearla */ DROP TABLE IF EXISTS [dbo].[Employees]; GO CREATE TABLE [dbo].[Employees]( [EmployeeID] [int] IDENTITY(1,1) NOT NULL, [SSN] [char](11) NOT NULL, [FirstName] [nvarchar](50) NOT NULL, [LastName] [nvarchar](50) NOT NULL, [Salary] [money] NOT NULL ) WITH ( SYSTEM_VERSIONING = ON, LEDGER = ON ); GO
Una vez creada la tabla, podemos verla en la interfaz marcada como ‘Updatable Ledger‘
USE DB_Ledger; GO /* Añadimos datos de prueba */ DECLARE @SSN1 char(11) = '795-73-9833'; DECLARE @Salary1 Money = 61692.00; INSERT INTO [dbo].[Employees] ([SSN], [FirstName], [LastName], [Salary]) VALUES (@SSN1, 'Catherine', 'Abel', @Salary1); DECLARE @SSN2 char(11) = '990-00-6818'; DECLARE @Salary2 Money = 990.00; INSERT INTO [dbo].[Employees] ([SSN], [FirstName], [LastName], [Salary]) VALUES (@SSN2, 'Kim', 'Abercrombie', @Salary2); DECLARE @SSN3 char(11) = '009-37-3952'; DECLARE @Salary3 Money = 5684.00; INSERT INTO [dbo].[Employees] ([SSN], [FirstName], [LastName], [Salary]) VALUES (@SSN3, 'Frances', 'Adams', @Salary3); DECLARE @SSN4 char(11) = '708-44-3627'; DECLARE @Salary4 Money = 55415.00; INSERT INTO [dbo].[Employees] ([SSN], [FirstName], [LastName], [Salary]) VALUES (@SSN4, 'Jay', 'Adams', @Salary4); DECLARE @SSN5 char(11) = '447-62-6279'; DECLARE @Salary5 Money = 49744.00; INSERT INTO [dbo].[Employees] ([SSN], [FirstName], [LastName], [Salary]) VALUES (@SSN5, 'Robert', 'Ahlering', @Salary5); DECLARE @SSN6 char(11) = '872-78-4732'; DECLARE @Salary6 Money = 38584.00; INSERT INTO [dbo].[Employees] ([SSN], [FirstName], [LastName], [Salary]) VALUES (@SSN6, 'Stanley', 'Alan', @Salary6); DECLARE @SSN7 char(11) = '898-79-8701'; DECLARE @Salary7 Money = 11918.00; INSERT INTO [dbo].[Employees] ([SSN], [FirstName], [LastName], [Salary]) VALUES (@SSN7, 'Paul', 'Alcorn', @Salary7); DECLARE @SSN8 char(11) = '561-88-3757'; DECLARE @Salary8 Money = 17349.00; INSERT INTO [dbo].[Employees] ([SSN], [FirstName], [LastName], [Salary]) VALUES (@SSN8, 'Mary', 'Alexander', @Salary8); DECLARE @SSN9 char(11) = '904-55-0991'; DECLARE @Salary9 Money = 70796.00; INSERT INTO [dbo].[Employees] ([SSN], [FirstName], [LastName], [Salary]) VALUES (@SSN9, 'Michelle', 'Alexander', @Salary9); DECLARE @SSN10 char(11) = '293-95-6617'; DECLARE @Salary10 Money = 96956.00; INSERT INTO [dbo].[Employees] ([SSN], [FirstName], [LastName], [Salary]) VALUES (@SSN10, 'Marvin', 'Allen', @Salary10); GO
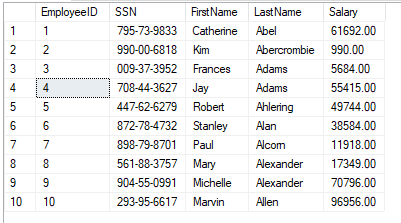
USE DB_Ledger; /*Si hacemos una consulta sobre todos los campos, vemos que nos aparecen los creados*/ SELECT EmployeeID, SSN, FirstName, LastName, Salary FROM dbo.Employees;
USE DB_Ledger; GO /* Pero existen campos ocultos que guardan información sobre el Ledger */ SELECT EmployeeID, SSN, FirstName, LastName, Salary, ledger_start_transaction_id, ledger_end_transaction_id, ledger_start_sequence_number, ledger_end_sequence_number FROM dbo.Employees; GO
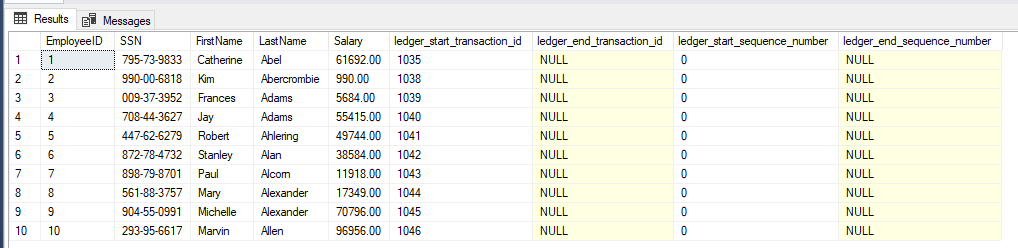
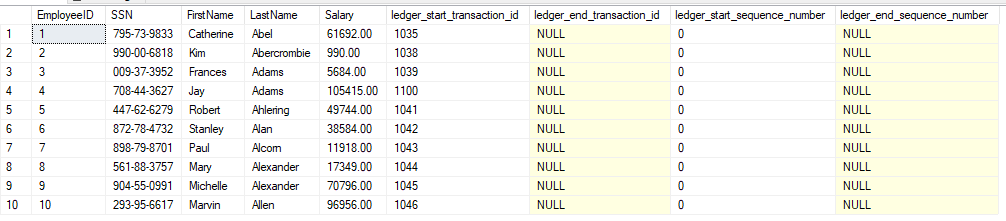
Vemos que algunas columnas están a 0 o NULL. Esto es porque aún no se han hecho cambios sobre esas columnas.
USE DB_Ledger; GO /* Si hacemos una consulta sobre la vista que se crea automáticamente cuando creas una tabla Ledger, vemos información oculta sobre la tabla además de la operación que se ha realizado sobre dicha columna */ SELECT * FROM dbo.Employees_Ledger; GO
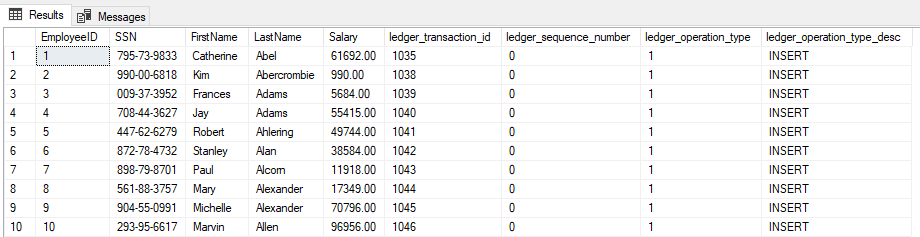
USE DB_Ledger; /* Definition of the view that is created. The historical tables of the Ledger have the format MSQQL_LedgerHistoryFor_[object_name]. You can see the use of the original table along with the historical data with the UNION ALL clausule */ CREATE VIEW [dbo].[Employees_Ledger] AS SELECT [EmployeeID], [SSN], [FirstName], [LastName], [Salary] , [ledger_start_transaction_id] AS [ledger_transaction_id] , [ledger_start_sequence_number] AS [ledger_sequence_number] , 1 AS [ledger_operation_type] , N'INSERT' AS [ledger_operation_type_desc] FROM [dbo].[Employees] UNION ALL SELECT [EmployeeID], [SSN], [FirstName], [LastName], [Salary] , [ledger_start_transaction_id] AS [ledger_transaction_id] , [ledger_start_sequence_number] AS [ledger_sequence_number] , 1 AS [ledger_operation_type] , N'INSERT' AS [ledger_operation_type_desc] FROM [dbo].[MSSQL_LedgerHistoryFor_901578250] UNION ALL SELECT [EmployeeID], [SSN], [FirstName], [LastName], [Salary] , [ledger_end_transaction_id] AS [ledger_transaction_id] , [ledger_end_sequence_number] AS [ledger_sequence_number] , 2 AS [ledger_operation_type] , N'DELETE' AS [ledger_operation_type_desc] FROM [dbo].[MSSQL_LedgerHistoryFor_901578250]
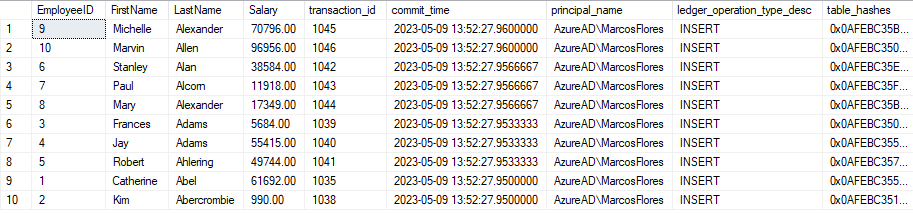
USE DB_Ledger; GO /* Nos podemos montar una consulta sencilla para extraer más información útil. Podemos observar que el único usuario que ha introducido datos es el mío */ SELECT e.EmployeeID, e.FirstName, e.LastName, e.Salary, dlt.transaction_id, dlt.commit_time, dlt.principal_name, e.ledger_operation_type_desc, dlt.table_hashes FROM sys.database_ledger_transactions dlt INNER JOIN dbo.Employees_Ledger e ON e.ledger_transaction_id = dlt.transaction_id ORDER BY dlt.commit_time DESC; GO
USE DB_Ledger;
GO
/* Ahora generamos el digest. El digest es un punto de referencia del estado actual de
los objetos del Ledger.
Utilizaremos el output para comprobar que el sistema no ha sido manipulado */
EXEC sp_generate_database_ledger_digest;
GO
/*
{"database_name":"DB_Ledger","block_id":0,"hash":"0x5F3D97F7C4C44E131447D081875193EC4B75C3563E97112DF74B2067D30692B2"
,"last_transaction_commit_time":"2023-05-09T13:52:27.9600000"
,"digest_time":"2023-05-09T12:32:11.2864004"}
*/
USE DB_Ledger; GO /* Con la siguiente consulta podemos ver el número de conjuntos de bloques enlazados criptográficamente. De momento sólo hay uno hasta generemos el próximo digest */ SELECT * FROM sys.database_ledger_blocks; GO

USE DB_Ledger; GO /* Estamos preparados ya para hacer una auditoría en condiciones. Comencemos actualizando el salario de uno de los empleados */ UPDATE dbo.Employees SET Salary = Salary + 50000 WHERE EmployeeID = 4; GO
USE DB_Ledger; GO /* Si hacemos una consulta normal a la base de datos, podemos ver el valor actualizado pero no quién lo ha hecho */ SELECT EmployeeID, SSN, FirstName, LastName, Salary, ledger_start_transaction_id, ledger_end_transaction_id, ledger_start_sequence_number, ledger_end_sequence_number FROM dbo.Employees; GO
USE DB_Ledger; GO /* Pero si realizamos la consulta sobre las tablas del sistema tal y como hemos hecho antes, vemos los cambios que ha sufrido el campo, el usuario que ha hecho los cambios y la hora */ SELECT e.EmployeeID, e.FirstName, e.LastName, e.Salary, dlt.transaction_id, dlt.commit_time, dlt.principal_name, e.ledger_operation_type_desc, dlt.table_hashes FROM sys.database_ledger_transactions dlt INNER JOIN dbo.Employees_Ledger e ON e.ledger_transaction_id = dlt.transaction_id ORDER BY dlt.commit_time DESC; GO
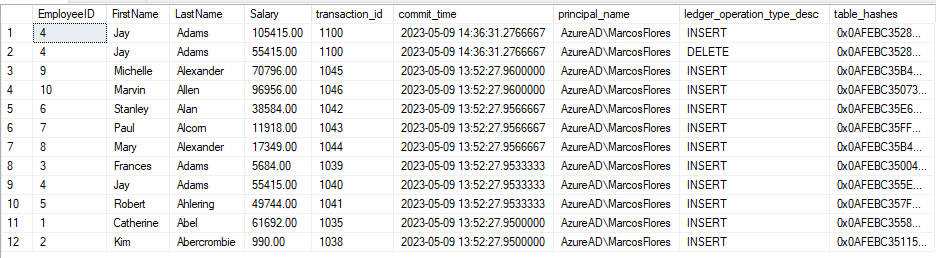
Podemos ver los diferentes valores que ha tenido el campo ‘Salary’ y la hora de la modificación (Insert y Delete).
USE DB_Ledger;
GO
/* Vamos a generar otro digest y nos volvemos a guardar el output */
EXEC sp_generate_database_ledger_digest;
GO
/*
{"database_name":"DB_Ledger","block_id":1,"hash":"0xC20F463A913BC01F76F14EA4CCA98C11180CEE8F4271AEA37382479A103CC17E"
,"last_transaction_commit_time":"2023-05-09T14:36:31.2766667"
,"digest_time":"2023-05-09T12:54:24.8138467"}
*/
USE DB_Ledger;
GO
/* Hora de verificar la integridad de los datos. Si ejecutamos el siguiente script con
el JSON del primer digest que generamos, el valor devuelto nos coincide con el id del
bloque de la consulta que lanzamos anteriormente */
EXECUTE sp_verify_database_ledger
N'{"database_name":"DB_Ledger","block_id":0,"hash":"0x5F3D97F7C4C44E131447D081875193EC4B75C3563E97112DF74B2067D30692B2"
,"last_transaction_commit_time":"2023-05-09T13:52:27.9600000"
,"digest_time":"2023-05-09T12:32:11.2864004"}'
GO
USE DB_Ledger; GO /* Si volvemos a consultar los bloques del Ledger, vemos que ahora nos aparecen dos */ SELECT * FROM sys.database_ledger_blocks;

USE DB_Ledger;
GO
/* También vemos que el campo previous_block_hash del segundo bloque (id 1) es el hash del primer digest
que obtuvimos */
/* Podemos verificar el output del segundo digest para ver que, efectivamente, pertenece al segundo
bloque con id 1 */
EXECUTE sp_verify_database_ledger
N'{"database_name":"DB_Ledger","block_id":1,"hash":"0xC20F463A913BC01F76F14EA4CCA98C11180CEE8F4271AEA37382479A103CC17E"
,"last_transaction_commit_time":"2023-05-09T14:36:31.2766667"
,"digest_time":"2023-05-09T12:54:24.8138467"}'
GO

Con esto hemos conseguido comprobar dos cosas:
- La primera es que los datos son válidos cuando se capturó el digest.
- La segunda es que los bloques internos deben coincidir con la actualización del salario del empleado número 4.
Y hasta aquí el post de hoy. Si te ha gustado, seguro que te interesan nuestros últimos artículos.
Actualiza MongoDB sin parada de servicio
La importancia de los Updates para SQL Server
Accede a tablas virtuales desde Microsoft Dataverse con SQL Server
Si necesitar mejorar u optimizar el rendimiento de tus BBDD, consulta nuestro servicio de SQL Server Health Check.

DBA SQL Server with 5 years of experience. Although I have advanced knowledge in various areas of SQL Server, I am also currently discovering MongoDB.
