
MongoDB, resuelve tus consultas lentas usando Profiler

Bienvenidos/as a un nuevo post en el blog de Aleson ITC.
Usualmente nos encontramos con operaciones que penalizan el rendimiento del servidor MongoDB pero que no son fácilmente detectables. Es por ello que en esta entrada observaremos cómo trabajar con profiler en MongoDB y la utilidad de éste.
También trataremos sobre cómo crear un índice y valoraremos su impacto en las consultas lentas recogidas en el profiler.
¿Qué es Profiler?
El profiler es simplemente una colección llamada system.profile que está desactivada por defecto. Cuando se activa, empieza a registrar operaciones CRUD como comandos de configuración y administración de la instancia. Es el lugar ideal dónde poder detectar consultas a mejorar.
Para tener un mayor control sobre lo que se registra en la colección del profiler, hay diferentes tipos de niveles:
- 0 –> Profiler está desactivado. Es decir, no se registra ningún tipo de comando.
- 1 –> Se le pueden aplicar filtros a Profiler. Por ejemplo, que guarde exclusivamente los comandos find que tardan más de 400ms.
- 2 –> Profiler registra todas las operaciones.
Por otra parte, Profiler utiliza espacio en disco ya que escribe los comandos en la colección system.profile y en el archivo de log de MongoDB. Es recomendable evitar el nivel 2 de Profiler y el 1 si no se tiene especificado un umbral robusto.
¿Cómo usar Profiler en MongoDB?
Vamos a aplicar un ejemplo. Para detectar consultas lentas habilitaremos Profiler en la base de datos que está experimentando estos problemas.
Para ello ejecutaremos la siguiente sentencia:
db.setProfilingLevel(1, {filter:{millis:{$gt:400}}})
Este comando hace que todas las operaciones que sobrepasen el umbral de 400ms se guarden en la colección system.profile.
Esperamos a que vuelva a ejecutarse la query lenta y observamos que el profiler la ha guardado. Hacemos un find en para ver la información que nos indica el profiler:
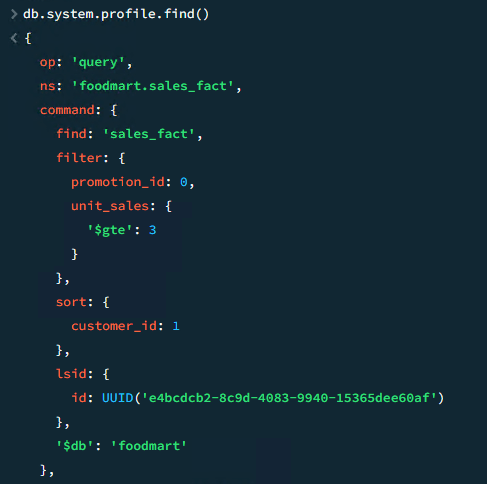
Resulta que la query lenta es la siguiente:
db.sales_fact.find({"promotion_id":0, "unit_sales":{$gte : 3}}).sort({"customer_id":1})
También nos indica que ha tardado 485 milisegundos y que el plan de ejecución ha sido un COLLSCAN. Esto nos muestra que no ha utilizado un índice y ha ido directamente a la tabla para abastecer la consulta.
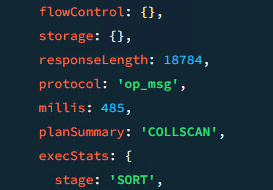
Es obvio que la query necesita un índice, pero, para crear uno necesitamos saber la regla ESR. Seguir dicha regla mejora la calidad de los índices.
¿Cómo corregir las consultas lentas?
La regla ESR especifica el orden de los campos a la hora de crear un índice y debe de ser:
- Equality: Es decir, el primer campo debe de ser el que tenga una condición de coincidencia exacta.
- Sort: El campo por los que se va a ordenar la query.
- Range: El campo por el que se filtra un rango de valores.
Entonces, siguiendo la regla ESR para crear un índice que sea óptimo para la consulta, vamos a crearlo de la siguiente forma:
db.sales_fact.createIndex({"promotion_id":1, "customer_id":1, "unit_sales":1})
Desde MongoDB Compass podemos observar el nuevo índice:

A continuación, vamos a ver si el tiempo de ejecución de la consulta anterior ha mejorado.
Primeramente, vamos a ejecutar un .explain() de la consulta para ver si el plan de ejecución contempla el índice nuevo:
db.sales_fact.find({"promotion_id":0, "unit_sales":{$gte : 3}}).sort({"customer_id":1}).explain()
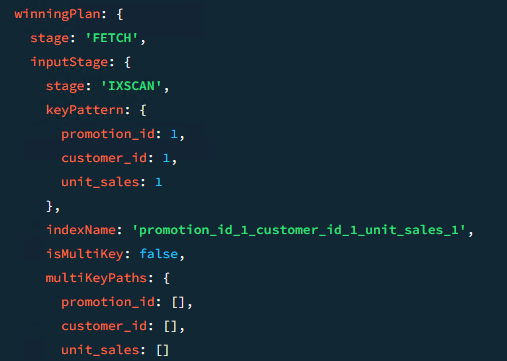
Todo indica a que la consulta va a utilizar el índice. Vamos a verificarlo utilizando el nivel 2 de profiler.
db.setProfilingLevel(2)
Lanzamos otra vez la query para que el profiler la guarde:
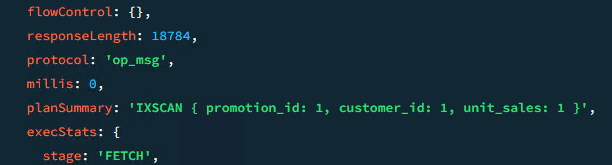
Efectivamente, la consulta utiliza el índice creado y actualmente tiene un tiempo de ejecución de 0 milisegundos. Después de realizar este proceso, no deberíamos de tener ningún tipo de problema a la hora de mejorar este tipo de consultas.
Con esto damos por finalizado el blog de hoy, espero que te haya sido útil.
¿Necesitas servicios de MongoDB? Contáctanos para concertar una reunión.

Data engineer with experience in SQL Server and MongoDB. Certified as a database administrator and data modeler in MongoDB, I specialize in designing and managing efficient and secure environments for database applications.
