
SQL Server 2025 mejora el rendimiento de JSON con índices y nuevas funciones

Evolución del soporte JSON en SQL Server
Desde SQL Server 2016, Microsoft introdujo soporte para datos JSON, permitiendo a los desarrolladores almacenar y consultar información semiestructurada dentro de bases de datos relacionales. Sin embargo, hasta ahora, trabajar con grandes volúmenes de datos JSON podía ser complicado y costoso en términos de rendimiento. SQL Server 2025 cambia radicalmente este panorama, incorporando mejoras significativas que hacen que JSON sea mucho más manejable.
Limitaciones del JSON en versiones anteriores
En versiones anteriores de SQL Server, el manejo de JSON resultaba complejo, ya que para indexar datos era necesario crear columnas calculadas que extrajeran valores específicos del documento. Esto aumentaba la dificultad de diseño y mantenimiento, obligaba a anticipar qué campos serían más consultados y generaba problemas de rendimiento en grandes volúmenes de datos, con alto consumo de CPU y tiempos de respuesta elevados. Estas limitaciones llevaron a muchos equipos a usar arquitecturas híbridas con bases NoSQL, incrementando la complejidad de la infraestructura.
Novedades de SQL Server 2025 para datos JSON
SQL Server 2025 supone un avance importante al permitir índices nativos directamente sobre campos JSON, eliminando la necesidad de columnas calculadas. Esto simplifica el diseño de las tablas, reduce el riesgo de inconsistencias y mejora de forma notable el rendimiento de las consultas, haciendo viable el uso intensivo de JSON en escenarios de alta concurrencia y posicionando a la plataforma como una opción sólida para aplicaciones modernas con esquemas flexibles.
Vamos a ponerlo a prueba.
Ejemplo práctico
Primeramente vamos a crear la tabla donde vamos a realizar las pruebas.
CREATE TABLE [HumanResources].[EmployeeJsonText]( [BusinessEntityID] [int] NOT NULL, [NationalIDNumber] [nvarchar](15) NOT NULL, [LoginID] [nvarchar](256) NOT NULL, [OrganizationNode] [hierarchyid] NULL, [OrganizationLevel] AS ([OrganizationNode].[GetLevel]()), [JobTitle] [nvarchar](50) NOT NULL, [BirthDate] [date] NOT NULL, [MaritalStatus] [nchar](1) NOT NULL, [Gender] [nchar](1) NOT NULL, [HireDate] [date] NOT NULL, [SalariedFlag] [dbo].[Flag] NOT NULL, [VacationHours] [smallint] NOT NULL, [SickLeaveHours] [smallint] NOT NULL, [CurrentFlag] [dbo].[Flag] NOT NULL, [rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL, [ModifiedDate] [datetime] NOT NULL, JsonData JSON);
Luego, crearemos otra tabla igual pero que más tarde indexaremos para ver la diferencia.
CREATE TABLE [HumanResources].[EmployeeJsonText_Indexed]( [BusinessEntityID] [int] NOT NULL, [NationalIDNumber] [nvarchar](15) NOT NULL, [LoginID] [nvarchar](256) NOT NULL, [OrganizationNode] [hierarchyid] NULL, [OrganizationLevel] AS ([OrganizationNode].[GetLevel]()), [JobTitle] [nvarchar](50) NOT NULL, [BirthDate] [date] NOT NULL, [MaritalStatus] [nchar](1) NOT NULL, [Gender] [nchar](1) NOT NULL, [HireDate] [date] NOT NULL, [SalariedFlag] [dbo].[Flag] NOT NULL, [VacationHours] [smallint] NOT NULL, [SickLeaveHours] [smallint] NOT NULL, [CurrentFlag] [dbo].[Flag] NOT NULL, [rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL, [ModifiedDate] [datetime] NOT NULL, JsonData JSON);
Ahora vamos a insertar datos desde una tabla existente a las dos tablas nuevas que acabamos de crear. Para no repetir todo el script, si lo quieres recrear, primero ejecuta el siguiente fragmento tal cual, y después cambia el nombre de tabla en el INSERT EmployeeJsonText por EmployeeJsonText_Indexed y vuelve a ejecutarlo.
INSERT INTO [HumanResources].[EmployeeJsonText](
[BusinessEntityID]
,[NationalIDNumber]
,[LoginID]
,[OrganizationNode]
,[JobTitle]
,[BirthDate]
,[MaritalStatus]
,[Gender]
,[HireDate]
,[SalariedFlag]
,[VacationHours]
,[SickLeaveHours]
,[CurrentFlag]
,[rowguid]
,[ModifiedDate]
,JsonData)
SELECT
BusinessEntityID
,NationalIDNumber
,LoginID
,OrganizationNode
,JobTitle
,BirthDate
,MaritalStatus
,Gender
,HireDate
,SalariedFlag
,VacationHours
,SickLeaveHours
,CurrentFlag
,rowguid
,ModifiedDate
,(
SELECT
BusinessEntityID as [BusinessEntityID]
,NationalIDNumber as [NationalIDNumber]
,LoginID as [LoginID]
,OrganizationNode as [OrganizationNode]
,JobTitle as [JobTitle]
,BirthDate as [BirthDate]
,MaritalStatus as [MaritalStatus]
,Gender as [Gender]
,HireDate as [HireDate]
,SalariedFlag as [SalariedFlag]
,VacationHours as [VacationHours]
,SickLeaveHours as [SickLeaveHours]
,CurrentFlag as [CurrentFlag]
,rowguid as [rowguid]
,ModifiedDate as [ModifiedDate]
FOR JSON PATH, WITHOUT_ARRAY_WRAPPER
) myjson
FROM AdventureWorks2025.HumanResources.Employee;
GO
Al insertar los datos, deberemos de ver que el campo JsonData se ve como la siguiente imagen:
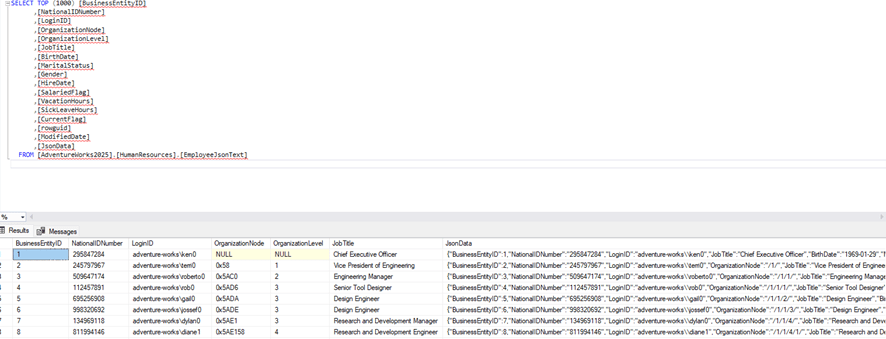
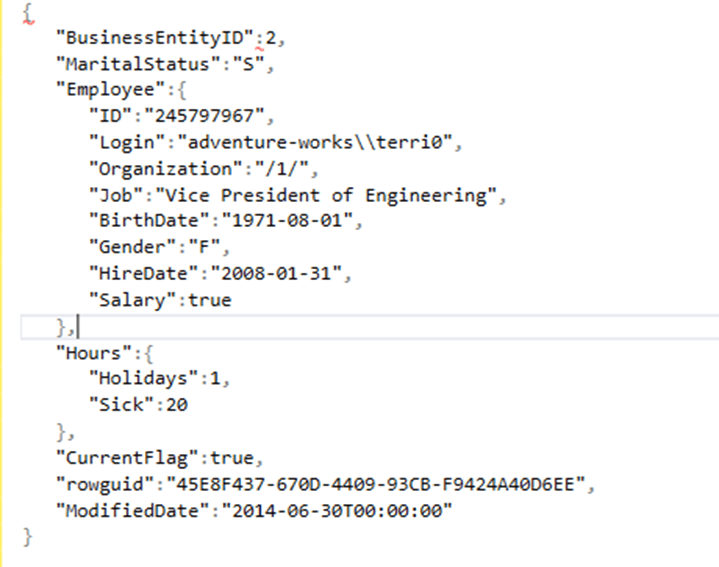
Si vemos con más detalle y lo parseamos, deberíamos de ver un formato parecido:
Y creamos el índice dentro del campo JsonData:
CREATE JSON INDEX ix_json ON HumanResources.EmployeeJsonText_Indexed(JsonData) FOR ('$.Employee.ID', '$.Employee.BirthDate', '$.Hours.Holidays');
Posteriormente, lanzamos las dos consultas para ver las diferencias en el motor de ejecución:
SET STATISTICS IO ON; SELECT LoginID FROM [HumanResources].[EmployeeJsonText] WHERE JSON_CONTAINS(JsonData,'295847284','$.Employee.ID') = 1; SELECT LoginID FROM [HumanResources].[EmployeeJsonText_Indexed] WHERE JSON_CONTAINS(JsonData,'295847284','$.Employee.ID') = 1;

Después de ver este resultado, podemos afirmar lo siguiente:
- Aunque tenga un índice, realiza un scan de la tabla.
- Se ha optimizado las lecturas de 32 logical reads a 3.
Pero, ¿Porque realiza un scan si tiene un índice para ese campo?
Vamos a ver como se almacena este ‘índice’ de tipo JSON.
En caso de ejecutar la siguiente consulta, vemos que se guarda como una tabla interna:
SELECT * FROM sys.objects WHERE name LIKE '%json%'

Es por esta razón por la que realiza ese scan y no el seek que siempre buscamos para optimizar al máximo una consulta con un índice al uso.
Beneficios de rendimiento en SQL Server 2025
Los beneficios de rendimiento que aporta SQL Server 2025 en el tratamiento de datos JSON son uno de los aspectos más destacados de esta versión. Las pruebas preliminares realizadas por Microsoft, junto con las experiencias de los primeros usuarios, muestran que las consultas sobre información almacenada en formato JSON pueden llegar a ser hasta diez veces más rápidas en comparación con versiones anteriores. Este incremento en la velocidad se debe principalmente a la incorporación de índices nativos sobre campos JSON y a la optimización interna de las funciones de consulta, lo que permite acceder a los datos de forma mucho más directa y eficiente.
En pocas palabras, trabajar con JSON en SQL Server 2025 deja de ser una solución de compromiso entre flexibilidad y eficiencia. Ahora es posible aprovechar la riqueza de los datos semiestructurados sin renunciar al rendimiento ni aumentar la dificultad en la administración de la base de datos, lo que abre la puerta a arquitecturas más simples, potentes y alineadas con las necesidades de las aplicaciones modernas.
Casos de uso prácticos de JSON en SQL Server
El soporte nativo de JSON con índices abre un abanico de posibilidades para desarrolladores y analistas de datos. Algunos escenarios incluyen:
- Aplicaciones modernas: Sistemas que almacenan datos semiestructurados, como configuraciones de usuario, logs de eventos o información de sensores, pueden ahora consultarse directamente desde SQL Server de forma rápida.
- Consultas en tiempo real: SQL Server 2025 permite buscar atributos JSON específicos en tiempo real, ideal para dashboards analíticos o aplicaciones con alta frecuencia de lectura.
- Almacén híbrido Relacional + NoSQL: Las organizaciones que buscan consolidar datos estructurados y semiestructurados pueden mantener todo dentro de SQL Server sin sacrificar rendimiento ni flexibilidad.
- IA y análisis avanzado: Los datos JSON estructurados pueden integrarse directamente con modelos de inteligencia artificial y aprendizaje automático, ofreciendo predicciones y análisis en tiempo real sin necesidad de ETL complejos.
Conclusión
Con estas capacidades, SQL Server deja de ser solo un almacén de datos relacional para convertirse en un plataforma híbrida capaz de manejar datos estructurados, semiestructurados y análisis avanzado.
Para las organizaciones que dependen de aplicaciones modernas, análisis en tiempo real o integración de IA, SQL Server 2025 ofrece una plataforma más flexible, rápida y eficiente, eliminando barreras históricas y simplificando la gestión de datos JSON a gran escala.
En definitiva, JSON deja de ser un “comodín” difícil de usar en SQL Server para convertirse en una herramienta potente y estratégica que combina lo mejor del mundo relacional y NoSQL, lista para el futuro de los datos.
Artículos de la Serie de SQL Server 2025
- Parte 1: Todas las novedades de SQL Server 2025
- Parte 2: Optimized Locking en SQL Server 2025
- Parte 3: Nuevo algoritmo compresión backup ZSTD para SQL Server 2025
- Parte 4: Change Event Streaming (CES) en SQL Server 2025
- Parte 5: SQL Server 2025 mejora el rendimiento de JSON con índices y nuevas funciones
- Parte 6: Vector Search en SQL Server 2025: tipo VECTOR y DiskANN
- Parte 7: Cómo usar expresiones regulares (REGEX) en SQL Server 2025
- Parte 8: Novedades de Intelligent Query Processing en SQL Server 2025
- Parte 9: Novedades de SQL Server Management Studio 22

Data engineer with experience in SQL Server and MongoDB. Certified as a database administrator and data modeler in MongoDB, I specialize in designing and managing efficient and secure environments for database applications.
