
Cómo usar expresiones regulares (REGEX) en SQL Server 2025

Introducción
Durante muchos años, trabajar con texto en SQL Server ha sido una tarea frustrante. Mientras algunos motores ofrecían soporte avanzado para expresiones regulares, otros debían conformarse con combinaciones de LIKE, PATINDEX, CHARINDEX o incluso funciones CLR para resolver problemas relativamente comunes.
En 2025, el escenario ha cambiado. En SQL Server 2025 se ha incorporado funciones REGEX nativas, permitiendo validar, limpiar y analizar texto complejo directamente.
¿Qué es REGEX?
Las expresiones regulares son un lenguaje especializado para describir patrones de texto. A diferencia de las comparaciones tradicionales, permiten identificar estructuras completas: formatos, repeticiones, rangos y combinaciones complejas de caracteres.
Cómo funcionan las expresiones regulares en T-SQL
Cuando SQL Server evalúa una expresión regular, lo hace carácter por carácter. No utiliza índices, no se beneficia de estadísticas y no puede optimizar el patrón internamente.
Esto significa que cada fila evaluada implica un coste real de CPU. Por este motivo, REGEX debe entenderse como una herramienta de precisión, no como una función para filtrar millones de registros en tiempo real.
Un patrón típico como:
[A-Za-z0-9._%+-]+ → Usuario del email@ → Separador obligatorio
[A-Za-z0-9.-]+ → Dominio\. → Punto literal
[A-Za-z]{2,} → extensión de al menos 2 caracteresFunciones REGEX disponibles en SQL Server
En SQL Server 2025, las principales funciones nativas son:
| REGEXP_LIKE | Devuelve un valor booleano que indica si la entrada de texto coincide con el patrón regex. |
| REGEXP_REPLACE | Devuelve una cadena de origen modificada reemplazada por una cadena de reemplazo, donde se encontró la aparición del patrón regex. |
| REGEXP_SUBSTR | Extrae partes de una cadena basada en un patrón de expresión regular. Devuelve Nésima aparición de una subcadena que coincide con el patrón regex. |
| REGEXP_INSTR | Devuelve la posición inicial o final de la subcadena coincidente, dependiendo de la opción proporcionada. |
| REGEXP_COUNT | Devuelve un recuento del número de veces que se produce el patrón regex en una cadena. |
| REGEXP_MATCHES | Devuelve una tabla de subcadenas capturadas que coinciden con un patrón de expresión regular con una cadena. Si no se encuentra ninguna coincidencia, la función no devuelve ninguna fila. |
| REGEXP_SPLIT_TO_TABLE | Devuelve una tabla de cadenas dividida, delimitada por el patrón regex. Si no hay ninguna coincidencia con el patrón, la función devuelve la cadena. |
Estas funciones permiten cubrir la gran mayoría de casos reales sin recurrir a soluciones externas.
Ejemplos reales en SQL Server
En entornos reales no siempre trabajamos con datos perfectamente estructurados. Es habitual encontrar tablas de logs, auditoria o integraciones donde varios datos vienen concatenados en una sola columna de texto.
Por ejemplo:
CRITICAL UserID=1004 Email=nombre.apellido@aleson.com Tel=699 123 456 Order=ORD-2025-004 Amount=999.99
Aquí tenemos información claramente estructurada (usuario, email, teléfono, pedido, importe), pero almacenada como texto libre.
Cuando necesitamos validar, buscar o analizar alguno de estos valores, primero debemos extraerlos y separarlos. En este tipo de escenarios, las funciones REGEXP en SQL Server permiten trabajar con datos desestructurados sin tener que rediseñar el sistema completo.
En este caso práctico veremos cómo hacerlo paso a paso.
EJEMPLOS:
REGEXP_REPLACE
SELECT
Event,
REGEXP_REPLACE(
REGEXP_SUBSTR(Event, 'Tel=[^ ]+'),
'[^0-9]',
''
) AS PhoneNumber
FROM System_events;

En este caso cogemos la parte del número Tel=[^ ]+ y elimina cualquier carácter que no sea un número.
REGEXP_LIKE
SELECT *
FROM System_events
WHERE REGEXP_LIKE(Event, '^(ERROR|CRITICAL)')
AND REGEXP_LIKE(Event, 'Amount=([5-9][0-9]{2}\.[0-9]{2})');

Aquí usamos LIKE para filtrar por las que empiecen por ERROR o CRITICAL y tengan un importe mayor de 500 o más.
REGEXP_SUBSTR
SELECT * FROM System_events

Estos son los datos que tenemos.
SELECT
REGEXP_SUBSTR(Event, '^[A-Z]+') AS Type,
REGEXP_SUBSTR(Event, '[0-9]{4}') AS UserID,
REGEXP_SUBSTR(Event, 'ORD-[0-9]{4}-[0-9]{3}') AS [Order],
REGEXP_SUBSTR(Event, '[0-9]+\.[0-9]{2}') AS Amount,
REGEXP_SUBSTR(Event, '[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}') AS Email
FROM System_events;
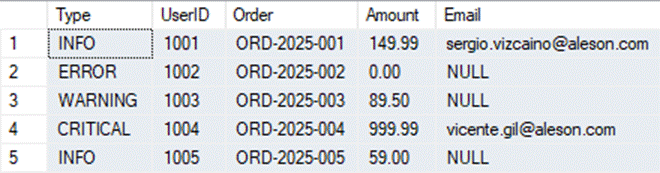
De tenerlos juntos los hemos estructurado en varios campos.
REGEXP_COUNT
SELECT
Id,
REGEXP_SUBSTR(Event, '[^ ]+@[^ ]+') AS Email,
REGEXP_COUNT(Event, '@') AS AtCount
FROM System_events
WHERE REGEXP_COUNT(Event, '@') >= 1;
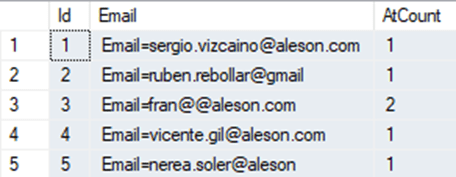
En este ejemplo validamos el Email contando los @ que hay, en este caso vemos que hay uno con 2 @.
SELECT
Id,
REGEXP_COUNT(
REGEXP_SUBSTR(Event, 'Tel=[^ ]+'),
'[0-9]'
) AS PhoneDigits
FROM System_events;
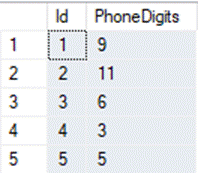
Podemos validar los números de teléfono contando cuantos dígitos tienen.
REGEXP_INSTR
SELECT
Id,
REGEXP_SUBSTR(Event, '[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}') AS Email
FROM System_events
WHERE REGEXP_INSTR(Event, '@') > 0;
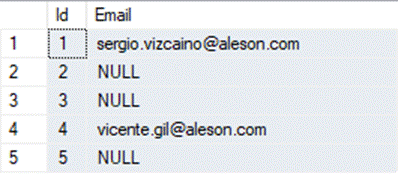
Esta consulta extrae el primer texto que tiene formato de email válido. Solo muestra las filas que contienen al menos una arroba @.
Conclusión
En 2025, SQL Server ofrece soporte nativo para expresiones regulares, lo que representa un avance importante. Sin embargo, REGEX no convierte a SQL Server en un motor de búsqueda de texto avanzado. Su papel es claro: validar, limpiar y preparar datos, no filtrar grandes volúmenes.
Artículos de la Serie de SQL Server 2025
Parte 1: Todas las novedades de SQL Server 2025
Parte 2: Optimized Locking en SQL Server 2025
Parte 2: Optimized Locking en SQL Server 2025
Parte 3: Nuevo algoritmo compresión backup ZSTD para SQL Server 2025
Parte 4: Change Event Streaming (CES) en SQL Server 2025
Parte 5: SQL Server 2025 mejora el rendimiento de JSON con índices y nuevas funciones
Parte 6: Vector Search en SQL Server 2025: tipo VECTOR y DiskANN
Parte 7: Cómo usar expresiones regulares (REGEX) en SQL Server 2025
Parte 8: Novedades de Intelligent Query Processing en SQL Server 2025
Parte 9: Novedades de SQL Server Management Studio 22
Parte 10: Data API Builder para Azure Databases

Junior Data Analyst.
