
Optimización de Tablas Delta en Fabric: Fragmentación

Optimizar el rendimiento de las tablas Delta es uno de los retos más habituales en entornos Fabric. En esta primera entrada establecemos el punto de partida: el entorno de pruebas, la metodología y las métricas que utilizaremos a lo largo de toda la serie para evaluar cada técnica de optimización.
Inicio
Para todas las pruebas de la serie utilizaremos la tabla salesorderdetail, con más de 1.300 millones de filas, cruzada contra la tabla Product mediante la siguiente consulta:
SELECT
p.name AS Product,
COUNT(*) AS Sales,
COUNT(DISTINCT SalesOrderID) AS DiffSales,
SUM(LineTotal) AS Total
FROM dbo.salesorderdetail_1000m AS a
JOIN dbo.Product AS p
ON p.ProductID = a.ProductID
WHERE p.ProductID IN (955, 748, 935)
GROUP BY p.name
Esta query nos servirá como referencia consistente a lo largo de toda la serie, permitiéndonos comparar el impacto real de cada técnica de optimización sobre el mismo conjunto de datos.
Cada vez que realicemos una modificación para mejorar el rendimiento de la tabla, registraremos los resultados en query_benchmark_results mediante el siguiente script, lo que nos permitirá comparar de forma objetiva el impacto de cada optimización a lo largo de toda la serie.
start_time = datetime.now()
start = time.time()
description = "raw"
query = f"""
SELECT
p.name AS Product,
COUNT(*) AS Sales,
COUNT(DISTINCT SalesOrderID) AS DiffSales,
SUM(LineTotal) AS Total
FROM dbo.salesorderdetail_1000m AS a
JOIN dbo.Product AS p
ON p.ProductID = a.ProductID
WHERE p.ProductID IN (955, 748, 935)
GROUP BY p.name
"""
df = spark.sql(query)
display(df)
end = time.time()
duration_seconds = end - start
print(duration_seconds)
result = spark.createDataFrame([
Row(
description=description,
query_text=query,
start_time=start_time,
duration_seconds=float(duration_seconds)
)
])
result.write.format("delta").mode("append").saveAsTable("dbo.query_benchmark_results")
Cada ejecución quedará registrada en la tabla query_benchmark_results en formato Delta, con su descripción, la query ejecutada, el momento de inicio y la duración en segundos, conformando así un histórico de rendimiento comparable entre todas las pruebas de la serie.
Paso 1: DESCRIBE DETAIL
Lanzaremos el siguiente código para obtener la información detallada de nuestra tabla:
df = spark.sql("DESCRIBE DETAIL demo_rendimiento_delta.dbo.salesorderdetail_1000m")
display(df)
El resultado obtenido es el siguiente:
| Campo | Valor |
|---|---|
format | delta |
id | 097856ec-5dd2-4d25-aaf8-265c7dae6470 |
name | spark_catalog.chimcobldhq2agac8l9kujh05kg4cga2a94k681d4114i815chimqrqve9imsp39dlkmarjkdtfm8pbcehgiap32ds.salesorderdetail_1000m |
description | — |
location | abfss://953b832a-cc6d-462b-a943-4cf7b1f44848@onelake.dfs.fabric.microsoft.com/529d84c4-794c-4bc8-b7da-5f7fa5a51e6f/Tables/dbo/salesorderdetail_1000m |
createdAt | 26/05/2026 00:58 |
lastModified | 27/05/2026 00:58 |
partitionColumns | [] |
clusteringColumns | [] |
numFiles | 128 |
sizeInBytes | 3.338.144.372 |
properties | {«delta.stats.extended.collect»:»true»,»delta.stats.extended.inject»:»true»} |
minReaderVersion | 1 |
minWriterVersion | 2 |
tableFeatures | [«appendOnly»,»invariants»] |
De todos los campos disponibles, los relevantes para evaluar el estado de la tabla y planificar su optimización son los siguientes:
numFiles: número de ficheros Parquet activos de la tabla. Un valor elevado en relación al tamaño de la tabla es indicativo de fragmentación.sizeInBytes: tamaño total de la tabla en bytes. Nos permite dimensionar la tabla y calcular el tamaño medio por fichero.partitionColumns: columnas utilizadas para el particionamiento físico de la tabla. Es importante verificar que el particionamiento tenga sentido para los patrones de consulta habituales.clusteringColumns: columnas utilizadas para Liquid Clustering. Debemos verificar que coincidan con los filtros más utilizados en las consultas.tableFeatures: nos indica características Delta habilitadas en la tabla.
Paso 2: Fragmentación
Lo primero que debemos revisar es si los datos de nuestra tabla están divididos en demasiados ficheros .parquet, lo que se conoce como fragmentación. Para comprobarlo, nos fijamos en dos valores obtenidos en el paso anterior:
numFiles: 128sizeInBytes: 3.338.144.372 (3,11 GB)
La regla general para determinar si existe fragmentación es la siguiente:
| Tamaño de la tabla | numFiles recomendado |
|---|---|
| 100 GB | < 1.000 |
| 500 GB | < 5.000 |
| 1 TB | < 10.000 |
En nuestro caso estamos muy por debajo del umbral de fragmentación. Sin embargo, aplicaremos igualmente el comando OPTIMIZE para asegurarnos de que los ficheros tienen el tamaño óptimo:
OPTIMIZE nombre_tabla

Tras ejecutar OPTIMIZE, el número de ficheros pasó de 128 a 4, pero el rendimiento no solo no mejoró, sino que empeoró: la query pasó de 20,26 a 24,17 segundos:
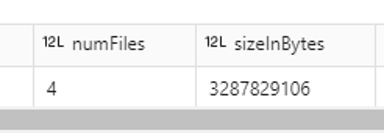

Menos ficheros no siempre significa mejor rendimiento. En este caso, consolidar demasiado los datos ha penalizado la consulta.
La documentación de Microsoft establece que el tamaño ideal de los ficheros .parquet en una tabla Delta es el siguiente:
| Tamaño de la tabla | Tamaño recomendado por fichero |
|---|---|
| < 10 GB | 128 MB |
| 10 GB – 10 TB | 256 MB – 512 MB |
| > 10 TB | 1 GB |
Con 4 ficheros para 3,11 GB, nuestros ficheros rondan los 800 MB, muy por encima del tamaño recomendado para este volumen de datos. Lo ideal sería tener ficheros de unos 128 MB, lo que nos lleva a trabajar con 16 ficheros. Para ajustar el número de particiones hay que recrear la tabla:
df = spark.read.table("demo_rendimiento_delta.dbo.salesorderdetail_1000m")
df.repartition(16) \
.write \
.mode("overwrite") \
.format("delta") \
.saveAsTable("demo_rendimiento_delta.dbo.salesorderdetail_1000m")
Aplicando repartition(16) obtenemos 16 ficheros de ~195 MB cada uno, y los resultados hablan por sí solos: la query mejora en 2,5 segundos, lo que supone una mejora del 12,3% respecto al estado anterior.
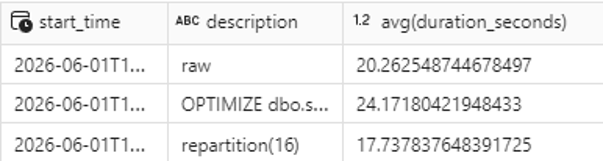
Conclusión
OPTIMIZE puede ser útil en determinados escenarios, pero como hemos comprobado, no es una solución universal. Recrear la tabla y probar diferentes tamaños de fichero .parquet en función del volumen de datos es siempre una buena estrategia de optimización.
En la siguiente entrada de la serie exploraremos ZORDER, partitionColumns y clusteringColumns, y veremos cómo estas técnicas pueden marcar una diferencia significativa en el rendimiento de nuestras tablas Delta.
FAQ – Preguntas frecuentes
¿Qué es la fragmentación en una tabla Delta?
La fragmentación ocurre cuando los datos de una tabla están divididos en demasiados ficheros .parquet de pequeño tamaño. Esto puede ralentizar las consultas porque el motor tiene que abrir y procesar un número elevado de ficheros para obtener el resultado.
¿Cómo sé si mi tabla Delta tiene fragmentación?
Con el comando DESCRIBE DETAIL sobre tu tabla puedes obtener el valor de numFiles y sizeInBytes. Dividiendo el tamaño total entre el número de ficheros obtienes el tamaño medio por fichero, que puedes comparar con los umbrales recomendados por Microsoft.
¿OPTIMIZE siempre mejora el rendimiento?
No. Como hemos comprobado en este blog, OPTIMIZE puede consolidar demasiado los ficheros y penalizar las consultas. En nuestro caso empeoró el rendimiento un 12%. Siempre es recomendable medir antes y después de aplicarlo.¿Cuál es el tamaño ideal de fichero .parquet en una tabla Delta?
¿Cuál es el tamaño ideal de fichero .parquet en una tabla Delta?
Microsoft recomienda ficheros de 128 MB para tablas de menos de 10 GB, entre 256 MB y 512 MB para tablas de hasta 10 TB, y 1 GB para tablas superiores a 10 TB.
Business Intelligence Expert Consultant. Specialising in creation of Data Warehouse, Analysis Services, Power BI, SSIS, SSRS and Databricks.
