
Carga Excels a SQL Server y Archivalos con Fecha y Hora

En mi primer post en el Blog, voy a hablar sobre uno de los procesos que utilizo casi día a día.
Se trata de cómo podemos archivar los datos de diferentes archivos Excel en una base de datos SQL Server, todo esto mediante SQL Server Integration Services (SSIS) renombrándolos con la fecha y hora en la que han sido procesados.
Vamos a seguir los siguientes pasos para la configuración de este proceso:
1. Creación de las bases del proyecto
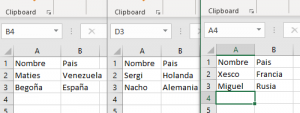
En primer lugar, necesitaremos los archivos Excel con más o menos la misma estructura de datos entre ellos (viene perfecto para archivar evoluciones de algún proceso, registros de algún tipo…). En este caso, he creado tres archivos con dos columnas igual:
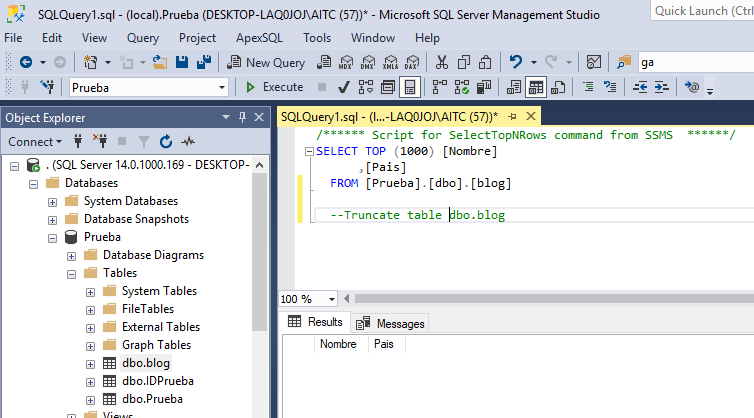
También, crearemos previamente una tabla en nuestro servidor con los campos a rellenar que sean lo más parecidos o idénticos a los de los Excel. Aunque es verdad que, durante el proceso, podemos realizar el mapping para relacionar las columnas con diferente nombre. En este caso vamos a utilizar la base de datos Prueba y la tabla dbo.Blog:
2. Creación de Directorios
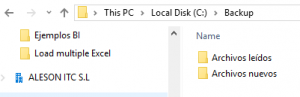
En esta fase, vamos a crear dos directorios:
- El primero, con la fuente sobre la cual el proyecto de SSIS va a leer la información (Archivos nuevos).
- El segundo, en el que nos gustaría archivar los ficheros ya leídos con el renombre que nos indicará la fecha y la hora en la que ha sido procesado (Archivos leídos).
3. Creación de un proyecto nuevo en SQL Server Data Tools
En esta fase, vamos a crear un proyecto nuevo utilizando SQL Server Data Tools. Si no disponéis del programa podéis descargarlo aquí.
Primero necesitamos crear un proyecto nuevo de SSIS y sobre el paquete que nos crea por defecto (paquete.dtsx) empezaremos a crear nuestro loop.
Dentro de Visual Studio disponemos de una ventana llamada SSIS Toolbox, disponemos de diferentes herramientas, en este proyecto vamos a utilizar principalmente cinco:
- Foreach Loop Container: Nos permite repetir en bucle el proceso que hemos especificado dentro del mismo.
- Data Flow Task: Herramienta que permite archivar un proceso en concreto.
- Excel Source: Permite especificar un archivo .xlsx como fuente de datos.
- Data Conversion: Permite cambiar el tipo de dato de cierta columna o la longitud del mismo.
- OLE DB Destination: Herramienta que permite especificar el destino de los datos después de ser procesados en el Data Flow Task.
Necesitaremos crear ciertas variables, ya que no se va a realizar solo sobre un fichero sino sobre tres (en nuestro caso, podrían ser más siempre que la estructura del Excel sea la misma).
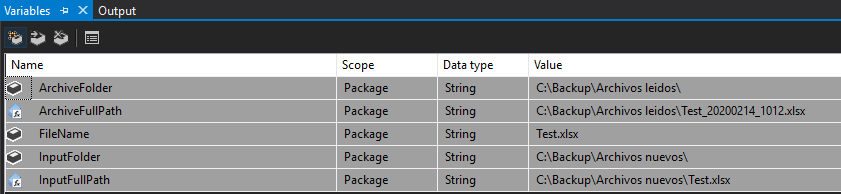
A continuación os muestro cuáles son las variables que vamos a necesitar en nuestro proyecto:
- ArchiveFolder: Nos proporciona el nombre de la carpeta la cual almacenará los archivos leídos y renombrados.
- FileName: Nombre de prueba que se le da al fichero que posteriormente será remplazado por el ArchiveFullPath.
- InputFolder: Nombre del repositorio del cual leerá los ficheros Excel.
- ArchiveFullPath: Determina la carpeta en la cual estará almacenado el fichero procesado con el nombre, fecha y hora en la cual ha sido leído, para esto necesitaremos la siguiente función:
@[User::ArchiveFolder]+Replace(@[User::FileName],".xlsx","")+"_"+Replace(Replace(Replace(SUBSTRING((DT_WSTR,50)(GETDATE()),1,16),"-","")," ","_"),":","")+".xlsx"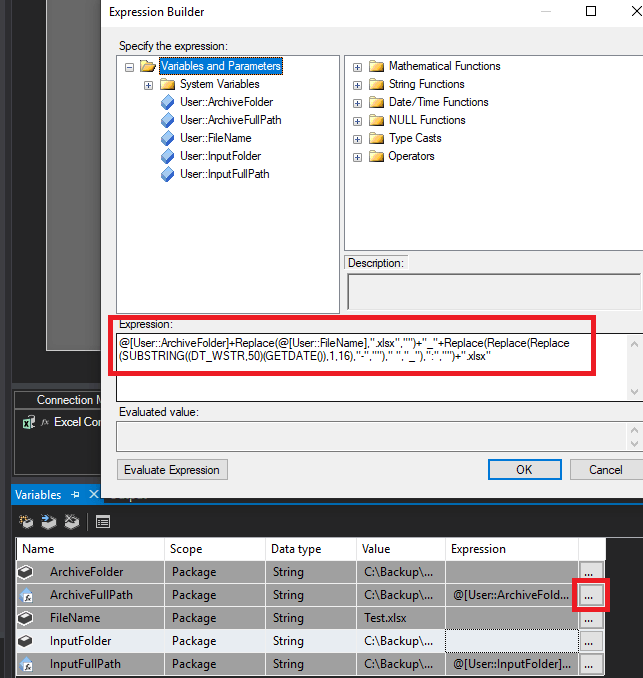
- InputFullPath: Dirección del repositorio de los archivos especificando que los tiene que leer, con la siguiente expresión, que nos indica que cogerá el repositorio y le añadirá el nombre del fichero.
@[User::InputFolder]+@[User::FileName]- Con las variables creadas, ya podemos realizar la conexión tanto al repositorio del cual va a leer los ficheros como al almacenamiento de datos en nuestro SQL Server.A continuación, vamos a seleccionar un fichero específico y, posteriormente mediante variables, haremos que lea todos los ficheros de la fuente.Seleccionamos la conexión de Excel (Excel Connection Manager) y clicamos sobre los 3 puntos en el apartado Expressions. Nos abrirá una ventana en la que tenemos que crear una Expresión que especificaremos desde un ExcelFilePath y otra vez sobre los 3 puntos crearemos la expresión juntando las dos variables. En este paso, cambiamos la expresión de la conexión Excel para que nos coja el nombre del repositorio en el cual se encuentran los archivos. Después, le añadimos la variable que hemos creado anteriormente para que coja los archivos que se encuentren en la carpeta, independientemente del nombre que posean.La siguiente conexión que necesitamos es la destinación en la que se van a almacenar todos los datos, en mi caso se encuentra en local, pero puede ser cualquier tipo de destino, incluido en Azure SQL Database.
En primer lugar, escogemos un Foreach Loop Container y crearemos un Data Flow Task.
Dentro del Data Flow Task tendemos que especificar una fuente sobre la que se va a realizar el proceso. Un proceso de Data Conversion (si es necesaria la transformación de datos) y un Destino en el cual se almacenarán los datos contenidos en los archivos Excel, llamada OLE DB Destination.
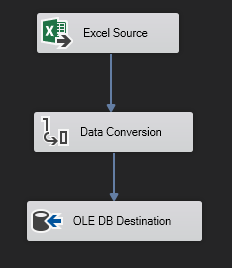
Esta sería la estructura básica del Data Flow Task que deberíamos llevar a cabo en el loop que pretendemos utilizar.
Una vez tenemos toda la parte del Data Flow Task realizada, vamos a configurar el Foreach Loop para que detecte los archivos en el repositorio especificado y sean procesados uno a uno por el Data Flow Task realizado previamente.
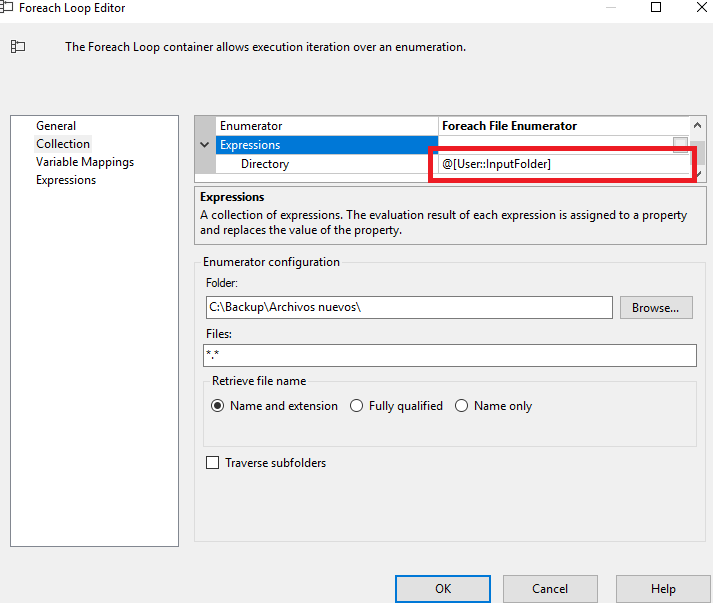
En el editor, simplemente tenemos que especificar la ruta de la carpeta sobre la cual tiene que efectuar el loop una vez leído el primer fichero, el nombre de los ficheros (o extensión) que queremos que coja, en este caso he puesto “*.*” pero podría ser “.xlsx” para evitar confusiones por si existen otro tipo de ficheros en el mismo repositorio.
En las expresiones tenemos que especificar también que se trata de un directorio y en la expresión, añadimos la variable InputFolder, que trataba de la ruta del directorio donde se encuentran los ficheros.
Por último, solo tenemos que darle las instrucciones de que hacer con los ficheros una vez están procesados.
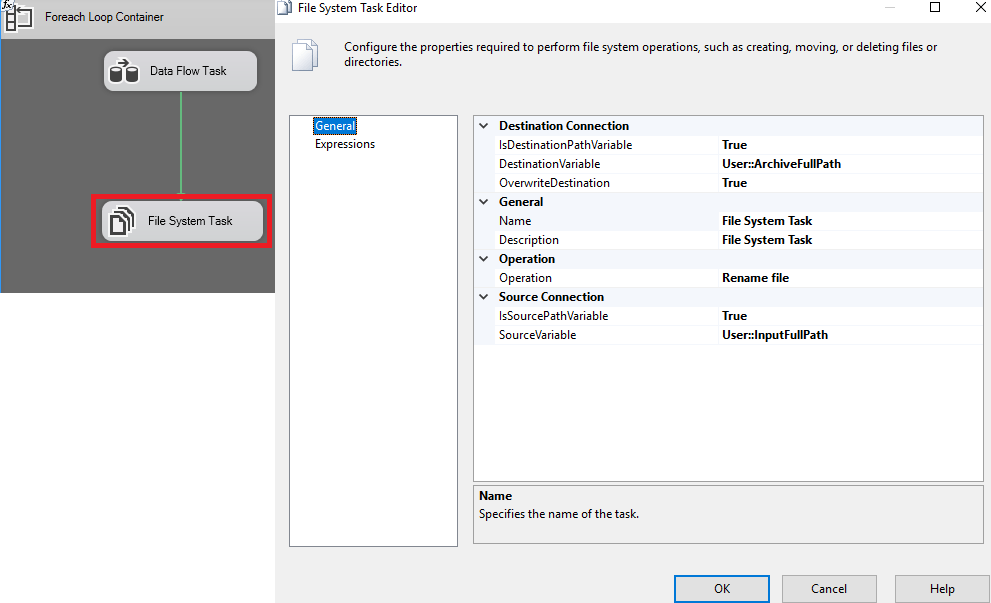
En esta ventana, le vamos a indicar que cuando acabe el loop anterior tiene que buscar el destino especificado, la operación que tiene que realizar es Rename File, el archivo quedará guardado con el nombre que tiene y además la fecha y la hora en la que ha sido añadido a la base de datos.
Una vez realizado el proceso de archivación nos pide si hay que hacer alguna cosa más, cambiamos la Source Connection a True y la fuente escogemos la variable InputFullPath.
4. Ejecución del Proyecto
En esta fase final, solo nos queda ejecutar el proyecto, comprobar si funciona correctamente y si los datos quedan registrados en nuestro SQL Server.
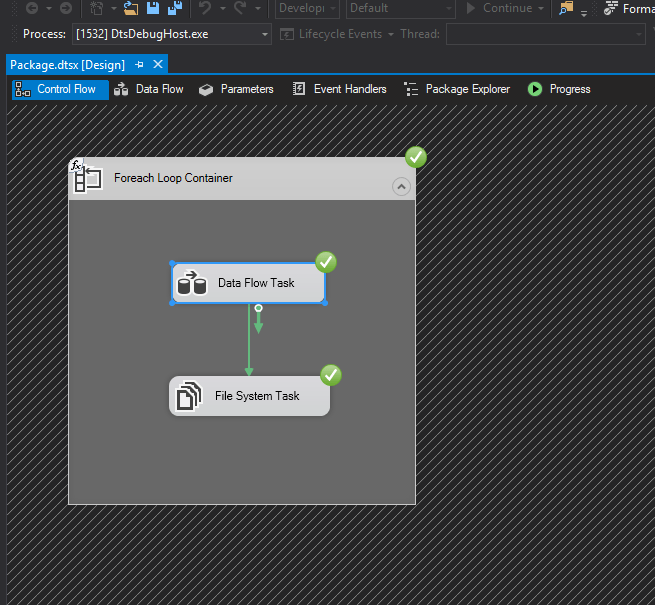
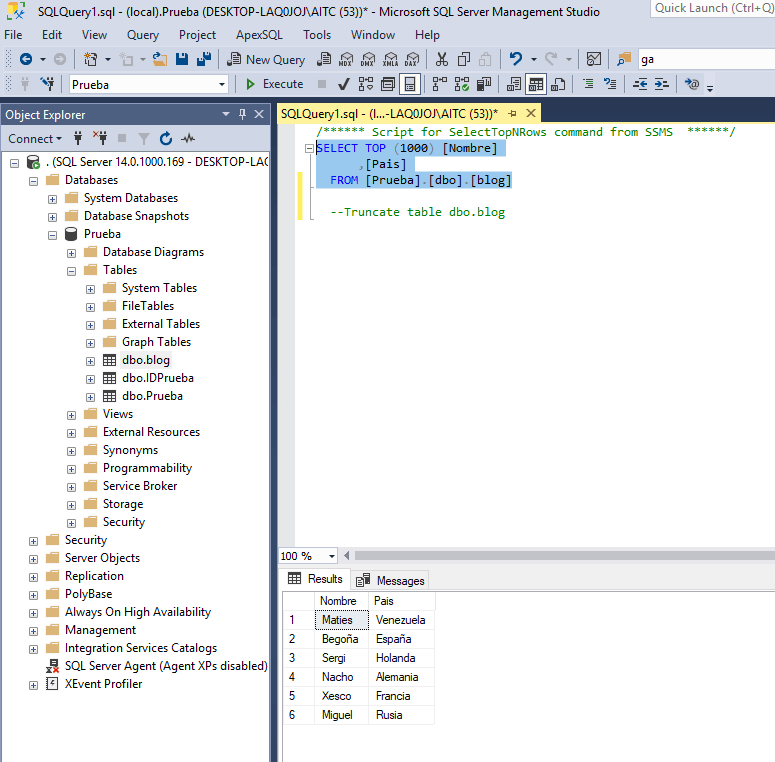
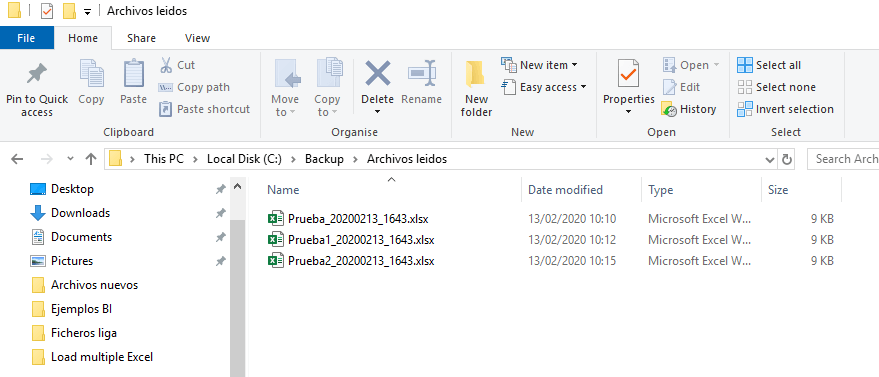
Si los datos se encuentran en la base de datos, solo nos quedaría comprobar el destino para ver si los archivos están renombrados con el script que hemos creado anteriormente en la variable.
Si quieres que ayudemos a tu negocio o empresa contacta con nosotros en info@aleson-itc.com o llámanos al +34 962 681 242
Data Analytics Analyst. Iniciando mi carrera profesional en el mundo de los datos.
