
Machine Learning 1.0.

En el post de hoy vamos a hablar sobre una de las ramas de estudio que cada vez está ganando más popularidad dentro de las ciencias de la computación: el aprendizaje automático o Machine Learning.
Muchos de los servicios que utilizamos en nuestro día a día como Google, Youtube, Netflix, Spotify o Amazon se valen de las herramientas que les brinda el Machine Learning para alcanzar un servicio cada vez más personalizado y lograr así ventajas competitivas sobre sus rivales.
En Machine Learning, los computadores aplican técnicas de aprendizaje estadístico para identificar patrones en los datos de manera automática. Estas técnicas pueden ser utilizadas para hacer predicciones con una alta precisión.
El primer proceso que involucra el Machine Learning es la exploración de datos. En esta etapa suelen ser de mucha utilidad las medidas estadísticas y la visualización de los datos, por ejemplo, los gráficos en 2 y 3 dimensiones para tener una idea visual de cómo se comportan nuestros datos. En este punto podemos detectar valores atípicos que debamos descartar; o encontrar las características que más influencia tienen para realizar una predicción. Es importante realizar un preanálisis para corregir los casos de valores faltantes e intentar encontrar algún patrón en los mismos, haciendo uso de las habilidades humanas, que nos facilite la construcción del modelo.
¿Por qué es importante explorar/visualizar los datos?
Disponer de muchos datos genera buenas generalizaciones, lo que nos lleva a buenos resultados incluso con un algoritmo simple. Pero hay ciertos peligros o advertencias a tener en cuenta:
- A veces tener más datos nos lleva a tener peores resultados.
- Es importante la calidad y variedad de los datos.
- Un algoritmo de aprendizaje con un rendimiento adecuado siempre es necesario.
- Lo más importante es extraer las características útiles de los datos.
- No hay un algoritmo de Machine Learning que lea los datos en bruto, sin explorar y tratar, y devuelva el mejor modelo.
La selección de atributos es el proceso por el cual seleccionamos un subconjunto de atributos (representados por cada una de las columnas en un dataset de forma tabular) que son más relevantes para la construcción del modelo predictivo sobre el que estamos trabajando. A las dimensiones en un conjunto de datos se les suelen llamar características, predictores, atributos o variables. Las visualizaciones de datos nos ayudan a la hora de hacer esta selección. A continuación, mostramos algunas de las visualizaciones más utilizadas:
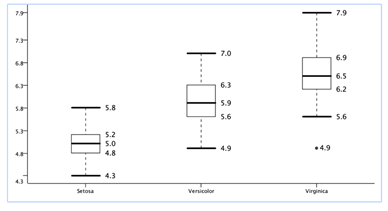
Box Plots: Muestran la distribución de una única dimensión particionada por la clase objetivo.
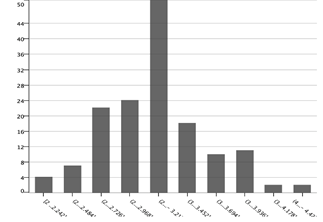
Histograma: Muestra la difusión de una sola característica. Coloca los valores en cajas y muestra la frecuencia. El número de cajas depende de la amplitud que te interese tomar.
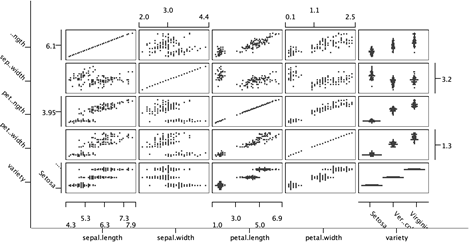
Matriz de diagrama de dispersión (Scatter matrix): Muestra múltiples relaciones en un gráfico. Permite visualizar las relaciones entre cada par de dimensiones ya que añadir otra dimensión permite ver más matices.
En la búsqueda de patrones en los datos, es donde el machine learning entra en juego. Mediante las visualizaciones apreciamos patrones en los datos pero los límites para delinearlos no son tan obvios. Los métodos empleados por machine learning usan el aprendizaje estadístico para identificar estos límites. Hay tres tipos de aprendizaje:
Aprendizaje Supervisado
En el aprendizaje supervisado, se nos da un conjunto de datos y ya sabemos cuál debe ser nuestra salida correcta, teniendo la idea de que existe una relación entre la entrada y la salida.
Los problemas de aprendizaje supervisados se clasifican en problemas de «regresión» y «clasificación«. En un problema de regresión, estamos tratando de predecir los resultados dentro de una salida continua, lo que significa que estamos tratando de asignar variables de entrada a alguna función continua. En un problema de clasificación, en cambio estamos tratando de predecir los resultados en una salida discreta. En otras palabras, estamos tratando de asignar variables de entrada en categorías discretas.
Aprendizaje No Supervisado
El aprendizaje no supervisado nos permite abordar los problemas con poca o ninguna idea de cómo deben ser nuestros resultados. Podemos derivar la estructura de datos, donde no necesariamente conocemos el efecto de las variables, agrupando los datos basados en relaciones entre las variables.
Con el aprendizaje sin supervisión no hay retroalimentación basada en los resultados de la predicción. La idea es que el algoritmo pueda encontrar por si solo patrones que ayuden a entender el conjunto de datos.
Aprendizaje por Refuerzo
En los problemas de aprendizaje por refuerzo, el algoritmo aprende observando el mundo que le rodea. Su información de entrada es el feedback o retroalimentación que obtiene del mundo exterior como respuesta a sus acciones. Por lo tanto, el sistema aprende a base de ensayo-error.
El proceso de crear un modelo también es conocido como entrenar un modelo. Aquí es donde comenzamos a utilizar las técnicas de Machine Learning realmente. En esta etapa nutrimos al o los algoritmos de aprendizaje con los datos que venimos procesando en las etapas anteriores. La idea es que los algoritmos puedan extraer información útil de los datos que le pasamos para luego poder hacer predicciones.
Los algoritmos que más se suelen utilizar en los problemas de Machine Learning son los siguientes:
- Regresión Lineal
- Regresión Logística
- Arboles de Decision
- Random Forest
- SVM o Máquinas de vectores de soporte.
- KNN o K vecinos más cercanos.
- K-means
Todos ellos se pueden aplicar a casi cualquier problema de datos y están todos implementados por la excelente librería de Python, Scikit-learn.
El paso siguiente sería evaluar el algoritmo. En esta etapa ponemos a prueba la información o conocimiento que el algoritmo obtuvo del entrenamiento del paso anterior. Evaluamos que tan preciso es el algoritmo en sus predicciones y si no estamos muy conforme con su rendimiento, podemos volver a la etapa anterior y continuar entrenando el algoritmo cambiando algunos parámetros hasta lograr un rendimiento aceptable.
Y hasta aquí el post de hoy, si queréis seguir aprendiendo Machine Learning no os perdáis mis próximas entradas.
Si quieres que ayudemos a tu negocio o empresa contacta con nosotros en info@aleson-itc.com o llámanos al +34 962 681 242

Business Intelligence Senior Consultant.
