
Migrando SQL Server a MongoDB con Relational Migrator

Bienvenidos/as a un nuevo artículo en el Blog de Aleson ITC. En el post de hoy vamos a hablar sobre realizar una migración relacional a No SQL.
Hoy en día existen numerosos motivos por los que migrar de una base de datos relacional, como MySQL, Oracle, PostgreSQL o SQL Server, a otro modelo que se adapte mejor a nuestras necesidades actuales y futuras. ¿Queremos innovar mientras modernizamos nuestra arquitectura de datos? ¿Queremos pasar a un esquema de datos mucho más flexible? ¿O simplemente queremos facilitarle la vida a nuestros desarrolladores? Sea cual sea la respuesta, MongoDB te lo pone fácil con su herramienta Relational Migrator, que nos ayuda a migrar cargas de trabajo relacionales a nuestro clúster en MongoDB Atlas.
Por qué migrar de relacional a NoSQL
Como se ha comentado, los motivos por los que una empresa decidiría migrar su sistema relacional a MongoDB son extensos.
Es un hecho que el activo más importante de una empresa son los propios datos. Cómo nos diferenciamos de la competencia y cómo obtenemos mayor ventaja competitiva está ligado al hecho de cómo se construye el software alrededor de los datos. Las aplicaciones modernas de hoy en día tienen diferentes requerimientos, como que el aplicativo soporte dispositivos móviles, tenga funcionamiento offline, sus datos se puedan explotar a nivel analítico, o sea altamente escalable.
La forma en la que utilizamos los datos ha cambiado, está cambiando, y cambiará a lo largo del tiempo, pero la infraestructura de datos subyacente no.
Las infraestructuras de datos comunes siguen utilizando bases de datos relacionales. Esto hace que adaptarse a la forma en la que explotamos el dato sea una tarea difícil, dado la propia rigidez de este tipo de sistemas.
Con la llegada de las bases de datos NoSQL y sobre todo de MongoDB, resolver los problemas a nivel referencial o estructural es una tarea mucho más sencilla.
Gracias al modelo documental, MongoDB nos proporciona agilidad y flexibilidad, haciendo que nuestro software se adapte a los cambios presentes y futuros.
MongoDB Relational Migrator
Relational Migrator es una herramienta que nos ayuda a dar el paso de arquitecturas relacionales a una arquitectura que se pueda adaptar mejor a nuestras necesidades futuras como MongoDB. Entre sus funciones están:
- Diseñar un esquema de MongoDB tomando como referencia uno relacional.
- Migrar datos desde base de datos relacionales a MongoDB mientras se realiza la transformación del esquema.
- Incluso te permite generar código para actualizar tu aplicación (C#, Java o Javascript).
Esta herramienta facilita en gran medida las migraciones y permite que una tarea tan compleja como es una migración de plataforma de datos sea sencilla de llevar a cabo.
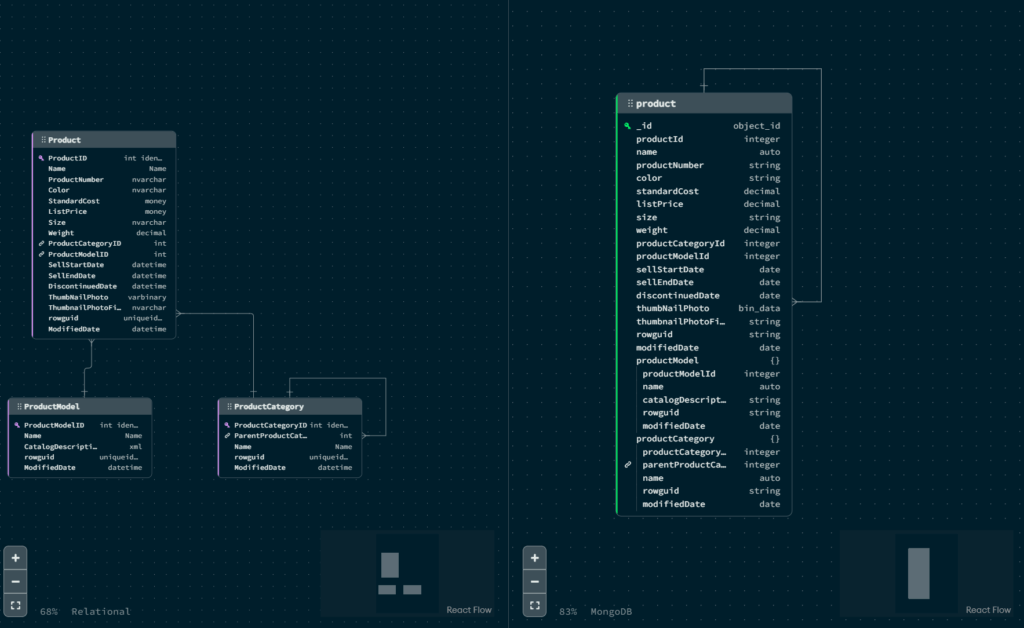
En la imagen anterior se puede apreciar como en la parte izquierda está el esquema relacional de origen compuesto por tres tablas. Y en la parte derecha el esquema del documento resultante en MongoDB.
Cómo funciona Relational Migrator
Relational Migrator tiene dos grandes casos de uso:
Migrar con Downtime
En este caso, si la aplicación no requiere de un tiempo de actividad constante, Relational Migrator realizará un snapshot de los datos y lo migrará desde ese momento. La aplicación que se va a migrar podrá admitir lecturas entrantes, pero no escrituras. La duración del proceso depende de la cantidad de datos y la velocidad de conexión.
Migrar sin Downtime
Migrar sin downtime es posible gracias a Change Data Capture (CDC). Si no es viable un mínimo tiempo de downtime y se necesita estar online durante el proceso de migración, se necesita realizar una sincronización continua. De este modo, cuando se inicia la sincronización, Relational Migrator realiza un snapshot de los datos y va realizando un seguimiento de las actualizaciones en tiempo real, prácticamente.
Sin embargo, existen también escenarios de migración en los que NO se recomienda utilizar Relational Migrator:
- Migrar múltiples aplicaciones sin downtime. En este escenario, las escrituras en origen están permitidas y se necesita que el CDC esté continuamente replicando.
- Migrar un data store operacional. Dependiendo de la carga de trabajo, podría implicar que el CDC debe estar corriendo indefinidamente.
En estos dos casos no se recomienda utilizar Relational Migrator por si solo, pero si lo unimos con una de las mejores tecnologías del mercado actual, como es Apache Kafka, esto cambia radicalmente.
Apache Kafka
Para ponernos en situación, Apache Kafka es una plataforma de datos en streaming que permite recoger, procesar y almacenar datos mediante eventos de manera indefinida.
Apache Kafka utiliza su herramienta de integración Kafka Connect para mover datos de una plataforma de datos a otra de manera escalable y sobre todo confiable mediante tareas.
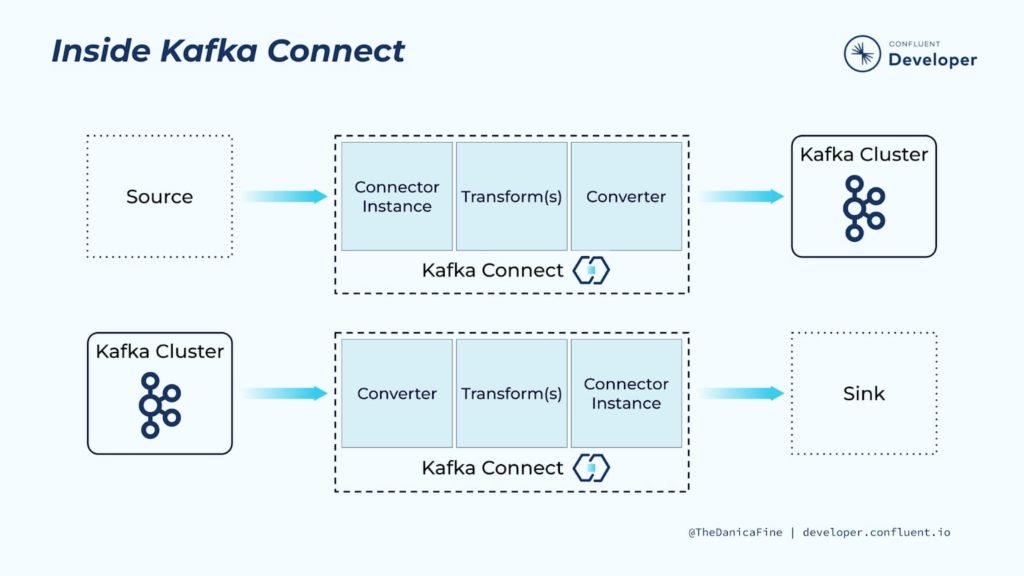
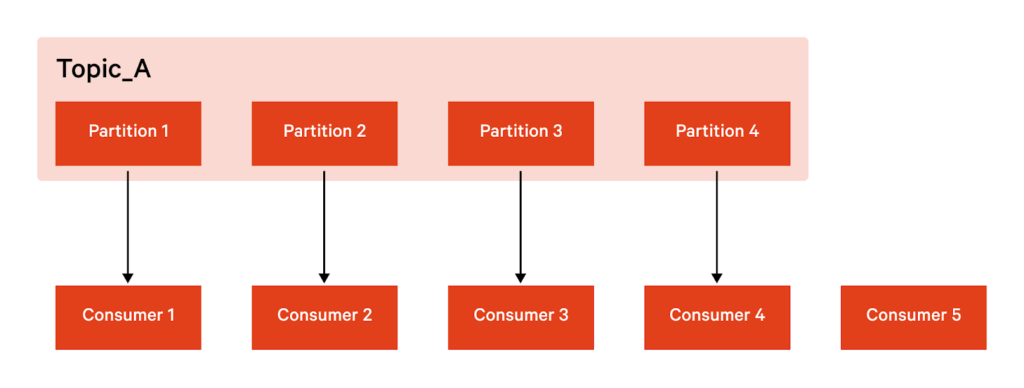
Kafka Connect es escalable porque te permite utilizar varios brokers (servidores) como cluster. Cada uno de estos brokers puede tener uno o más workers, que básicamente son instancias de Java Virtual machine (VJM) que ejecutan la lógica del conector. Además, Kafka Connect también dispone de resiliencia, y lo consigue con un diseño distribuido y replicado. Kafka almacena, organiza y distribuye los datos mediante topics. Cada topic está dividido en particiones, de manera que cada una está replicada en múltiples nodos redundantes.
MongoDB Relational Migrator y Apache Kafka
Ahora que conocemos los componentes, vamos a ver un poco más en profundidad cómo funciona Relational Migrator con Apache Kafka.
Primero que nada, se debe utilizar Kafka como capa de transporte cuando pensamos que la migración tendrá un tamaño considerable y de larga duración. Gracias a Kafka, el trabajo de sincronización podrá recuperarse si en algún momento algún componente falla.
Relational Migrator hace las veces de conector y receptor para Kafka Connect. Internamente, utiliza un conector Debezium para realizar la captura de datos en origen mientras que es el propio Relational Migrator el que los interpreta y transforma y los envía al clúster MongoDB destino.
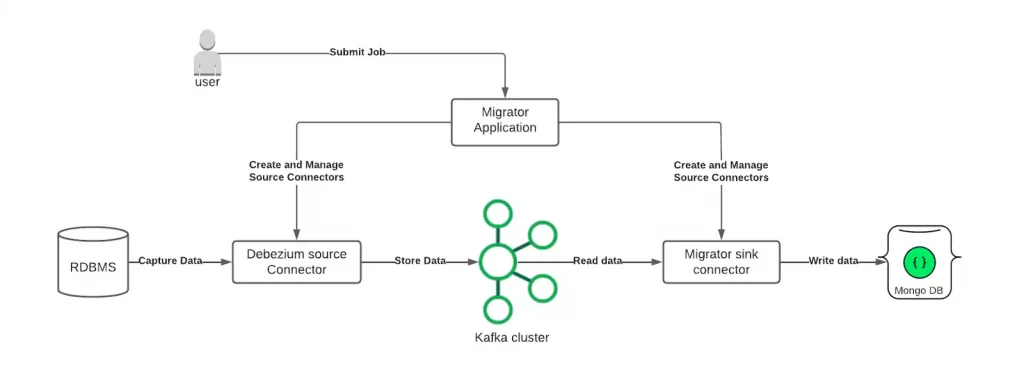
Funcionamiento de Relational Migrator
Una vez hayamos integrado Kafka con Relational Migrator siguiendo la guía de MongoDB y arrancado el servicio, conectaremos con la base de datos a migrar. En nuestro caso, una instancia SQL Server ejecutándose on premise.
Acto seguido nos pedirá seleccionar las tablas que queremos migrar.
Ahora viene la parte interesante. En el apartado que hay que definir el esquema, lo primero que vemos es que podemos cambiar el nombre de las colecciones y los campos. Siguiendo estilos de escritura como el camelCase o TitleCase. Aunque también podemos optar a dejarlo como está originalmente.
También nos permite seleccionar el mapeado inicial, en el cual puedes seleccionar el mismo esquema que ya dispones en el modelo relacional. Empezar con el esquema recomendado (puede que te incruste tablas que no has seleccionado para cumplir con el modelo relacional) o empezar sin modelo relacional.
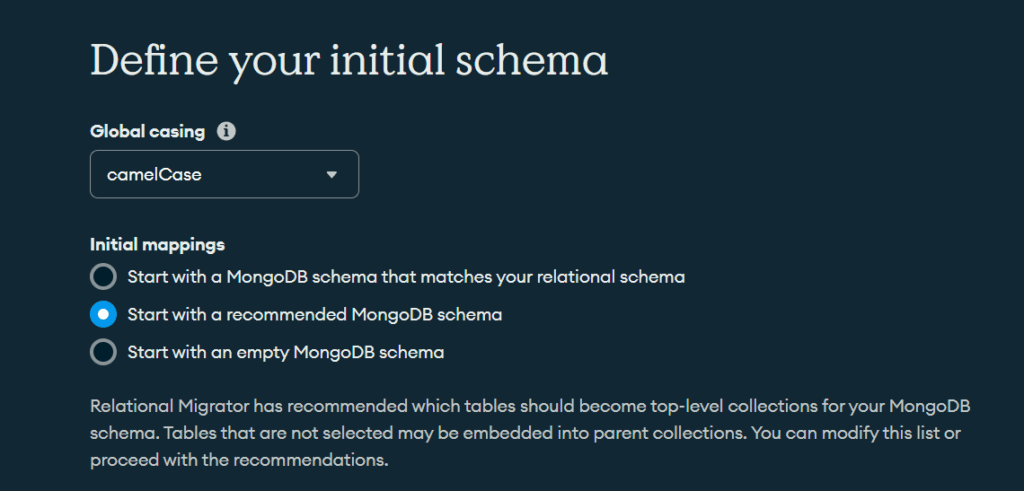
Después de dar nombre a nuestro proyecto, nos aparecerá el diagrama de mapeado. En este es donde podemos ver el esquema origen y destino, y modificar este último si lo vemos procedente.
Podemos cambiar la colección destino a una tipo time series, añadir campos, crear campos calculados o elegir si la tabla se migra en forma de nuevos documentos o optar una estrategia que implique incrustar el documento en el documento padre o en el del hijo dependiendo de la relación de su clave ajena.
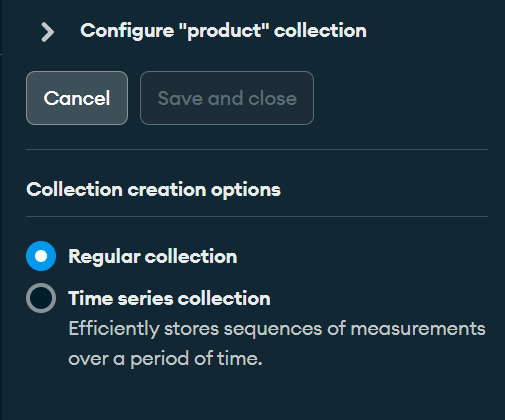
Configuración de colecciones
Incluso podemos configurar cómo se genera el campo _id en las colecciones, desde que se autogenere cada vez que se inserta un documento a que utilice la clave primaria del registro.
Una vez hayamos configurado el mapeo inicial de los objetos, pasamos al apartado donde podremos generar el código para nuestro aplicativo con el objetivo de utilizar las colecciones que vamos a insertar como objetos. Por ejemplo, podemos generar una clase en Java Spring para las colecciones con todos sus métodos habituales, como el constructor, los setters y getters e incluso el equal.
Llegó el momento de crear el job de migración. Si hemos configurado Kafka con Relational Database correctamente, nos debería salir un mensaje al lado del botón Create migration job indicándonos que el despliegue está a cargo de Kafka.
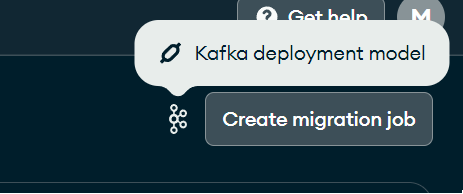
Creación de Jobs
El primer paso para la creación del job es conectar a la base de datos origen, cosa que ya hemos hecho en pasos anteriores. Después nos pedirá conectarnos al MongoDB Atlas destino.
Una vez conectados, es hora de elegir si queremos optar por una sincronización continua o una ocasional mediante snapshot. Incluso podemos borrar las colecciones antes de la migración, aunque no es necesario puesto que Kafka ya detecta internamente mediante offsets y puntos de snapshot qué documentos se han migrado y cuáles no en el consumidor. Evitando así que se inserten registros repetidos si se vuelve a ejecutar el job.
Si no hemos realizado correctamente el cambio a Kafka como modo de despliegue, nos aparece un mensaje indicando que Relational Migrator está corriendo en single process.
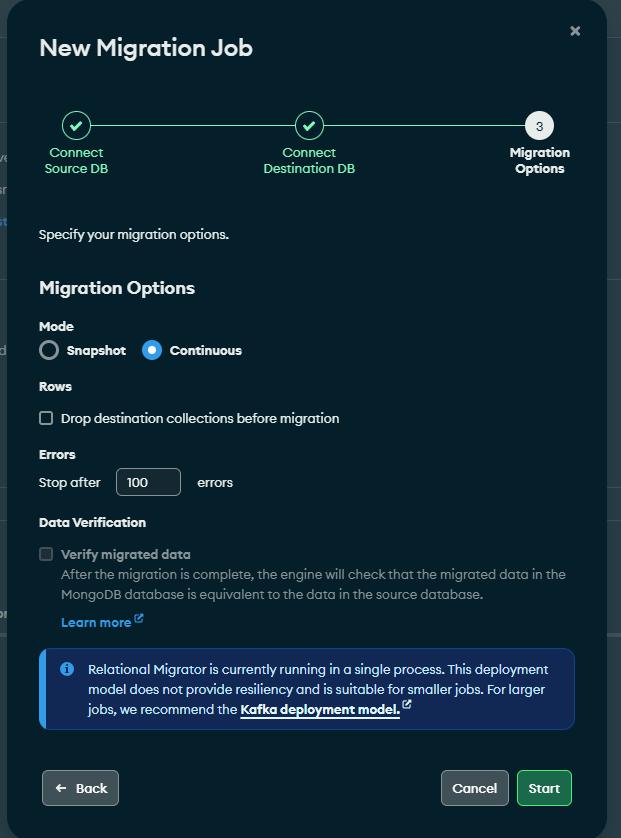
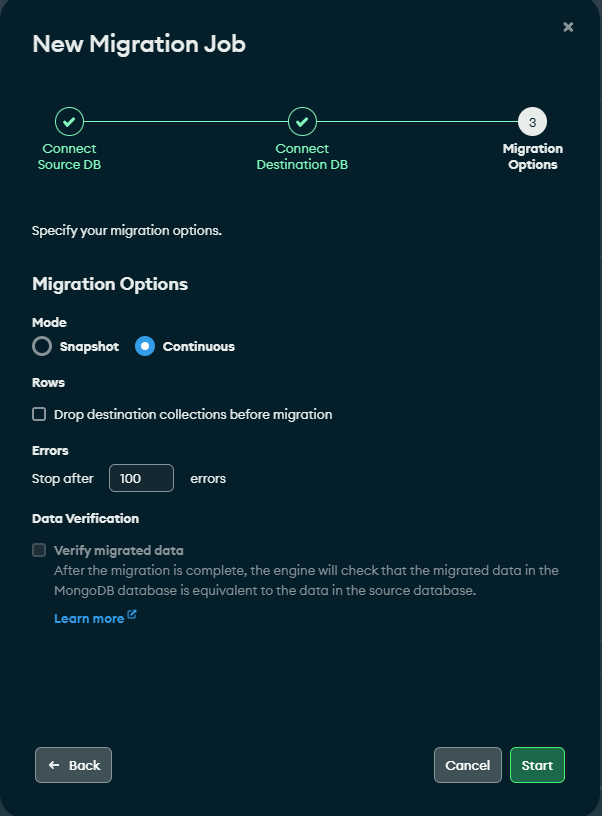
En este punto, ya solo nos queda arrancar la tarea y dejar a Relational Migrator hacer el resto.
Y hasta aquí el post de hoy. Esperamos que haya sido útil a la hora de empezar a trabajar con la herramienta de Relational Migrator.
¿Necesitas servicios de MongoDB? Contáctanos para más información.

DBA SQL Server with 5 years of experience. Although I have advanced knowledge in various areas of SQL Server, I am also currently discovering MongoDB.
