
Migrating SQL Server to MongoDB with Relational Migrator

Welcome to a new article on the Aleson ITC Blog. In today’s post we are going to talk about performing a relational migration to No SQL
Nowadays there are very reasons to migrate from a relational database, such as MySQL, Oracle, PostgreSQL or our always beloved SQL Server, to another model that better adapts to our current and future needs. Do we want to innovate while modernizing our data architecture? Do we want to move to a much more flexible data schema? Or do we just want to make life easier for our developers? Whatever the answer is, MongoDB makes it easy for you with its Relational Migrator tool, which helps us to migrate relational workloads to our MongoDB Atlas cluster.
Why migrate from relational to NoSQL
As we said, the reasons why a company would decide to migrate its relational system to MongoDB are extensive.
It is a fact that the most important asset of a company is its data. How we differentiate ourselves from the competition and how we gain greater competitive advantage is tied to how software is built around data. Today’s modern applications have different requirements, such as that the application supports mobile devices, has offline operation, its data can be exploited at an analytical level, or is highly scalable.
The way we use data has changed, is changing, and will change over time, but the underlying data infrastructure has not.
Common data infrastructures still use relational databases. This makes adapting to the way we exploit data a difficult task, given the rigidity of this type of systems.
With the arrival of NoSQL databases and especially MongoDB, solving problems at a referential or structural level is a much simpler task.
Thanks to the document model, MongoDB provides us with agility and flexibility, making our software adapt to present and future changes.
MongoDB Relational Migrator
Relational Migrator is a tool that helps us take the step from relational architectures to an architecture that can better adapt to our future needs like MongoDB. Among its functions are:
- Design a MongoDB schema taking a relational one as a reference.
- Migrate data from relational database to MongoDB while performing schema transformation.
- It even allows you to generate code to update your application (C#, Java or Javascript).
This tool greatly facilitates migrations and allows a task as complex as a data platform migration (paradigm change included) to be simple to carry out
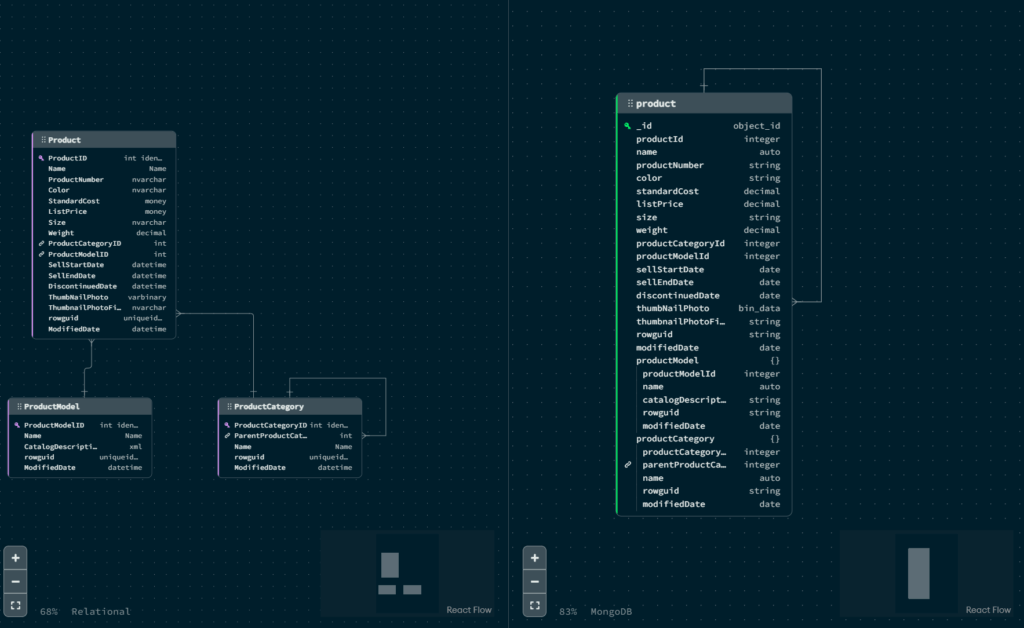
In the previous image you can see how on the left side is the source relational schema composed of three tables, and on the right side is the schema of the resulting document in MongoDB.
How Relational Migrator works
Relational Migrator has two big use cases:
Migrate with Downtime
In this case, if the application does not require constant uptime, Relational Migrator will take a snapshot of the data and migrate it from that moment on. The application to be migrated will be able to support incoming reads, but not writes. The duration of the process depends on the amount of data and connection speed.
Migrate without Downtime
Migrating without downtime is possible thanks to Change Data Capture (CDC). If minimal downtime is not feasible and you need to be online during the migration process, continuous synchronization is needed. In this way, when the synchronization starts, Relational Migrator takes a snapshot of the data and tracks updates in practically real time.
However, there are also migration scenarios in which it is NOT recommended to use Relational Migrator:
- Migrate multiple applications without downtime. In this scenario, source writes are allowed and the CDC is required to be continuously replicating.
- Migrate an operational data store. Depending on the workload, it could mean that the CDC must be running indefinitely.
In these two cases, it is not recommended to use Relational Migrator by itself, but if we combine it with one of the best technologies on the current market, such as Apache Kafka, this changes.
Apache Kafka
To put ourselves in a situation, Apache Kafka is a streaming data platform that allows you to collect, process and store data through events indefinitely. Apache Kafka uses its Kafka Connect integration tool to move data from one data platform to another in a scalable and, above all, reliable way using tasks.
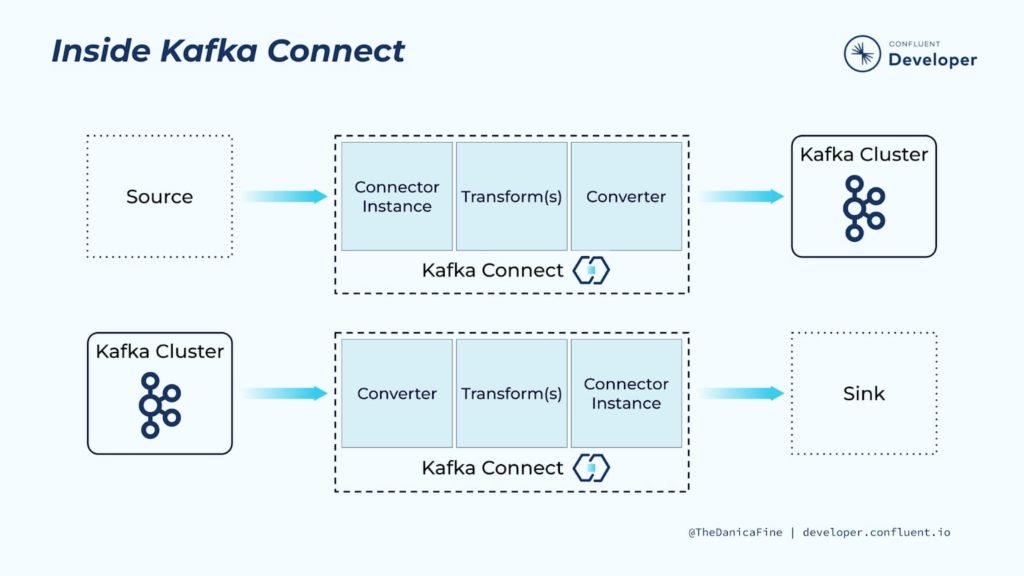
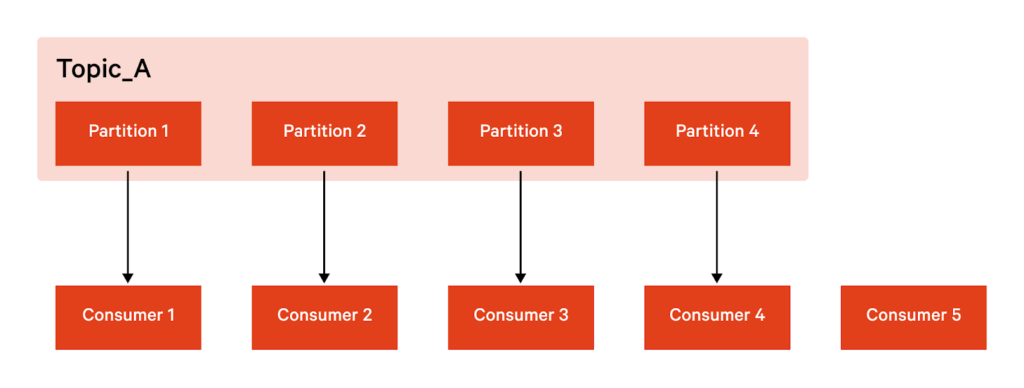
Kafka Connect is scalable because it allows you to use several brokers (servers) as a cluster. Each of these brokers can have one or more workers, which are basically Java Virtual machine (VJM) instances that execute the connector logic. In addition, Kafka Connect also has resilience, and it achieves this with a distributed and replicated design. Kafka stores, organizes and distributes data using topics. Each topic is divided into partitions, so that each one is replicated on multiple redundant nodes.
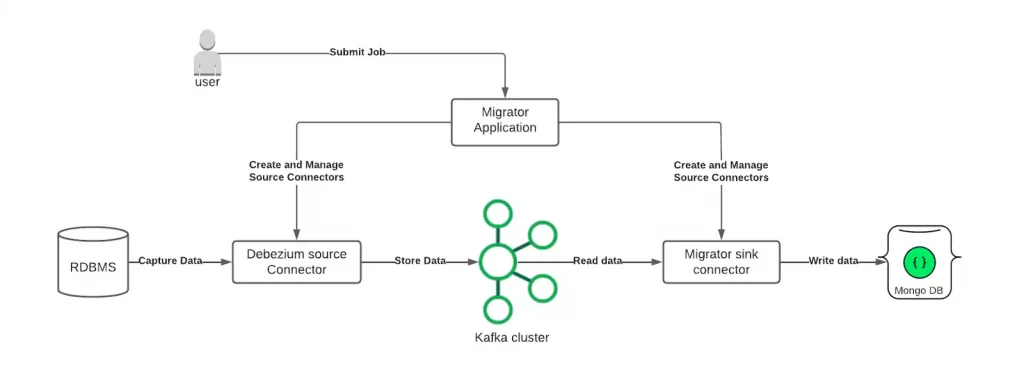
Mongo Relational Migrator and Apache Kafka
Now that we know the components, let’s look a little more in depth at how Relational Migrator works with Apache Kafka. First of all, Kafka should be used as a transport layer when we think that the migration will be of considerable size and long duration. Thanks to Kafka, the synchronization job can be recovered if any component fails at any time. Relational Migrator acts as a connector and sink for Kafka Connect. Internally, it uses a Debezium connector to capture data at the source while the Relational Migrator itself interprets and transforms it and sends it to the destination MongoDB cluster.
Relational Migrator operation
Once we have integrated Kafka with Relational Migrator following the guide provided by MongoDB and once we have started the service, the first thing it asks us to do is connect to the source database of the migration. In our case, a SQL Server instance running on premise. It will then ask us to select the tables we want to migrate. Now comes the interesting part. In the section that has to define the schema, the first thing we see is that we can change the name of the collections and fields following writing styles such as camelCase or TitleCase, although we can also choose to leave it as it is originally.
It also allows us to select the initial mapping, in which you can select the same schema that you already have in the relational model, start with the recommended schema (it may embed tables that you have not selected to comply with the relational model) or start without a model. relational.
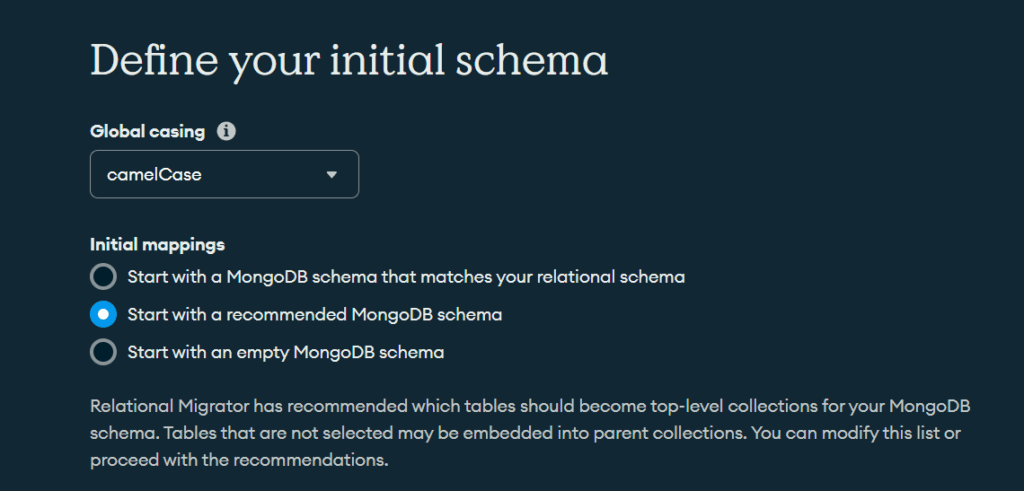
After naming our project, the mapping diagram will appear, where we can see the source and destination scheme, and modify the latter if we see it appropriate.
We can change the destination collection to a time series type, add fields, create calculated fields or choose if the table is migrated in the form of new documents or choose a strategy that involves embedding the document in the parent or child document depending on the relation of its foreign key.
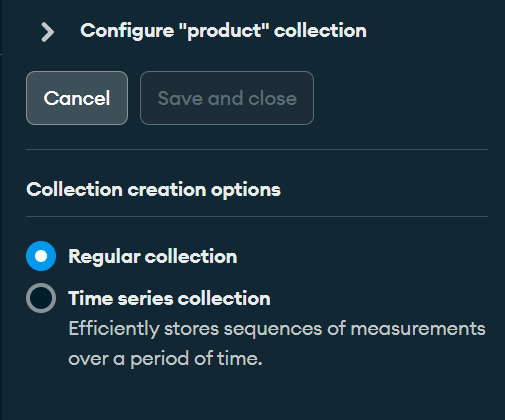
Collections configuration
We can even configure how the _id field is generated in collections, from autogenerating it every time a document is inserted to using the primary key of the record.
Once we have configured the initial mapping of the objects, we move on to the section where we can generate the code for our application in order to use the collections that we are going to insert as objects. For example, we can generate a class in Java Spring for collections with all its usual methods, such as the constructor, setters and getters, and even equal.
It is time to create the migration job. If we have configured Kafka with Relational Database correctly, a message should appear next to the Create migration job button indicating that the deployment is in charge of Kafka.
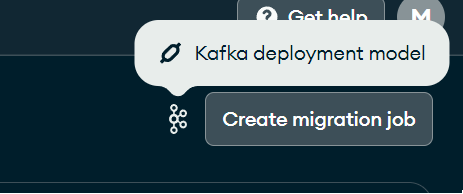
Creating Jobs
The first step in creating the job is to connect to the source database, something we have already done in previous steps. Then it will ask us to connect to the destination MongoDB Atlas.
Once connected, it is time to choose whether we want to opt for continuous synchronization or occasional snapshot synchronization. We can even delete the collections before the migration, although it is not necessary since Kafka already detects internally through offsets and snapshot points which documents have been migrated and which have not in the consumer, thus preventing repeated records from being inserted if it is run again. the job.
If we haven’t correctly made the change to Kafka as the deployment mode, a message appears indicating that Relational Migrator is running in single process.
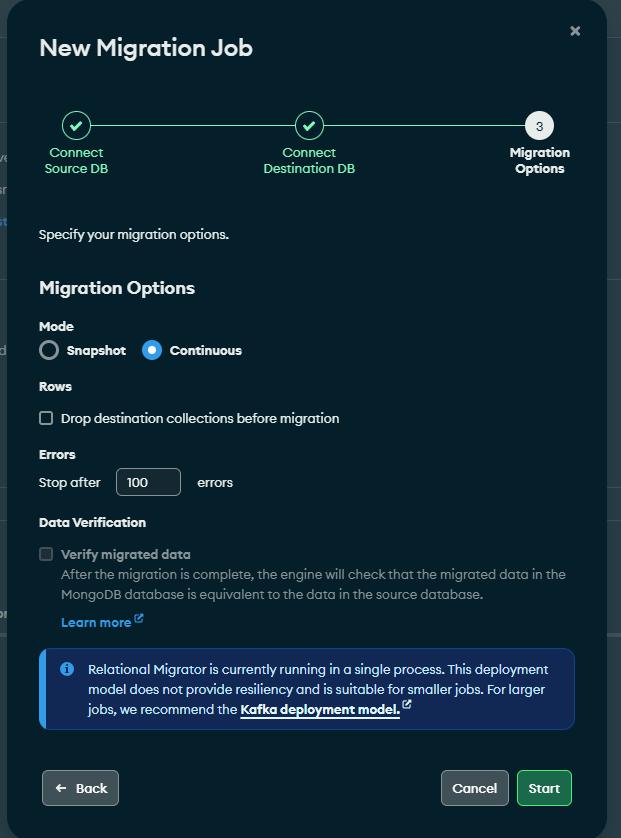
f you have it configured correctly, this message will not appear.
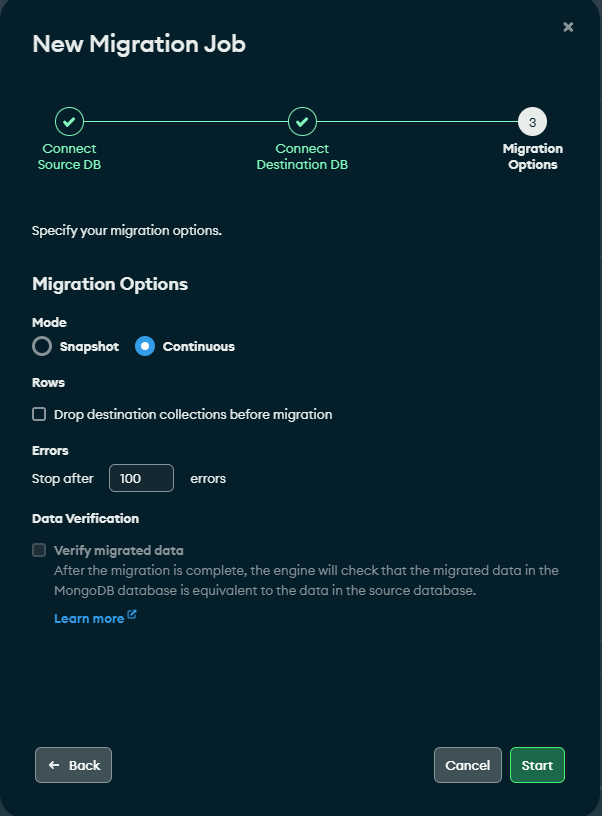
At this point, all we have to do is start the task and let Relational Migrator do the rest.
And here the post today. We hope it has been useful as you start working with the Relational Migrator tool.
Do you need MongoDB services? Contact us for more information.

DBA SQL Server with 5 years of experience. Although I have advanced knowledge in various areas of SQL Server, I am also currently discovering MongoDB.