
Revoluciona SQL Server con ColumnStore Index
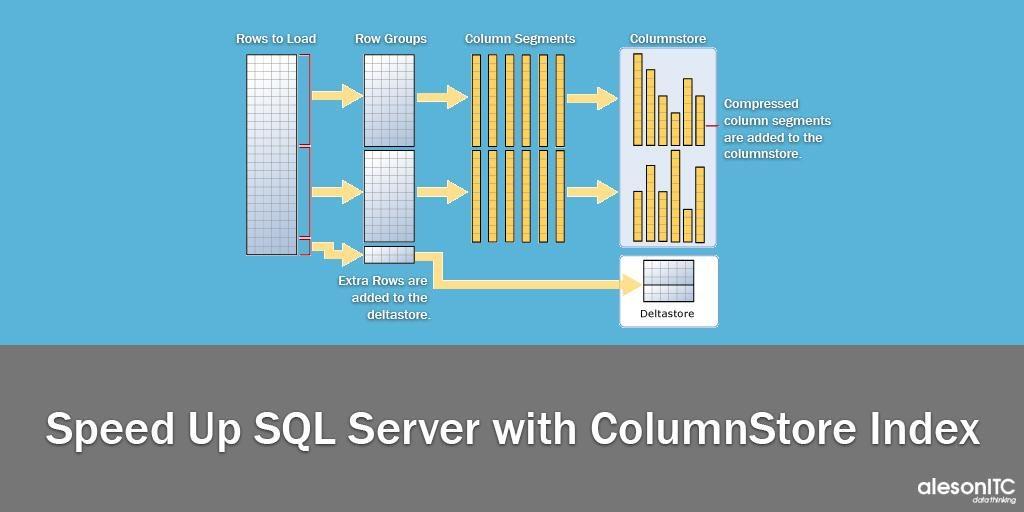
Vamos a realizar una serie de posts sobre los índices orientados a columnas para SQL Server (ColumnStore Index), este se trata de un post introductorio en el cual vamos a englobar los diferentes aspectos que trataremos posteriormente en cada uno de ellos.
Los índices ColumnStore dieron los primeros signos de vida en SQL Server 2012, pero no fue hasta 2016 cuando comenzaron a desarrollar su máximo potencial.
Estos índices pueden llegar a ser hasta 10 veces más rápidos que los índices tradicionales orientados a filas (RowStore Index) y, hablando del tamaño que ocupan, la compresión de datos puede ser hasta 7 veces mayor en relación a los datos sin comprimir.
1.- Características Index ColumnStore SQL Server 2012
Para que nos hagamos una idea, en sus inicios:
- Se añade la posibilidad de crear un índice Non-Clustered ColumnStore por tabla.
- El índice Non-Clustered ColumnStore era de solo lectura. Eso era un impedimento ya que si queríamos realizar una operación INSERT, UPDATE o DELETE, debíamos borrar el índice ColumnStore, realizar las operaciones pertinentes y después crearlo de nuevo.
- Los índices de almacenamiento de columnas comenzaron a utilizar la compresión por segmentos.
2.- Características añadidas en SQL Server 2014
Más adelante, llegamos a la versión SQL Server 2014, donde los cambios sobre los índices ColumnStore fueron los siguientes:
- Se añade la posibilidad de crear un índice Clustered ColumnStore por tabla, con la restricción de que la tabla no puede contener más índices.
- Se pueden actualizar, insertar o borrar datos en tablas que contengan Clustered ColumnStore Index.
- Se añade la opción de compresión “Archive”, que comprime todavía más los índices ColumnStore para tablas con un bajo número de operaciones DML (INSERT, UPDATE, DELETE).
3.- Características añadidas en SQL Server 2016
Es en la versión SQL Server 2016 donde muestran un verdadero potencial:
- A partir de esta versión las tablas que contengan Non-Clustered Columnstore index se pueden actualizar sin tener que borrar y crear el índice cada vez.
- La tablas que tuvieran Clustered ColumnStore Index, ahora podrán incorporar uno o varios Non-Clustered RowStore Index.
- Se incorpora la posibilidad de crear ColumnStore Index en tablas en memoria. Se puede crear cuando se genere la tabla o agregarlo posteriormente con el comando ALTER TABLE.
- Compatibilidad con las Primary Keys y Foreign Keys en los Clustered ColumnStore Index.
- Los índices ColumnStore tienen una opción para retrasar la compresión, de manera que si han de modificarse filas no repercuta demasiado en el rendimiento del servidor.
4.- Características añadidas en SQL Server 2017
- A partir de SQL Server 2017, un Clustered ColumnStore Index puede contener una columna calculada no persistente.
Desde nuestra experiencia como consultores, hemos analizado decenas de servidores SQL desde versiones 2012 hasta 2017 y no hemos visto apenas aplicados este tipo de índices. Se puede considerar que no son muy conocidos y se ignora su capacidad de mejoría en el rendimiento de las consultas.
5.- Index ColumnStore vs Index RowStore
La pregunta que todos esperábamos, lo primero que se nos viene a la cabeza es:
¿Cuándo usaremos índices de almacenamiento basado en columnas (Index ColumnStore) y cuándo usaremos índices de almacenamiento basado en filas (Index RowStore)?
Al pensar en esta pregunta, vemos que ambos índices pueden convivir en los mismo entornos. La diferencia es que los índices Column Store son más adecuados en tablas OLAP (On-Line Analytical Processing) y los índices RowStore son más adecuados para las tablas OLTP (On-Line Transactional Processing). Se usarán índices Clustered Column Store en tablas de hechos y tablas de grandes dimensiones de datos DataWarehouse. A su vez, podemos utilizar índices Non-Clustered ColumnStore junto con índices RowStore en entorno OLTP, este uso conjunto se denomina Real-Time Operational Analytics.
Un problema que podemos encontrar es un mayor número de bloqueos al tratar de realizar operaciones de INSERT, UPDATE o DELETE en las tablas con Clustered ColumnStore Index. De ahí que se deban usar dichos índices en entornos OLAP y no OLTP.
Normalmente, el resultado de las búsquedas a estas tablas son unas pocas filas, lo que reduce el número de Lecturas/Escrituras de los discos.
Para finalizar, comentaros que en entradas siguientes veremos las principales características de los índices ColumnStore, hablaremos de composición interna de los índices, velocidad, compresión, Real Time Operational Analytics..
Si quieres que ayudemos a tu negocio o empresa contacta con nosotros en info@aleson-itc.com o llámanos al +34 962 681 242

Azure Data Engineer con más de 7 años de experiencia. Conocimiento de múltiples herramientas y enfocado en el mundo del dato. Experto en tuning de queries y mejora de rendimiento de Base de Datos. Profesional apasionado por la tecnología y los deportes al aire libre. En mi tiempo libre, me encontrarás jugando vóley playa o disfrutando con nuevos videojuegos.
