
💹 Despiezando los índices Column Store

En el post de hoy, hablaremos de la estructura de los índices Column Store, así como la forma en la que estos trabajan internamente para facilitar su comprensión.
1.- Índice columnstore.
Refresquemos la definición de almacén de columnas o columnstore. Los índices de almacén de columnas son el estándar para almacenar y consultar las tablas de hechos de almacenamiento de datos de gran tamaño. Como su propio nombre indica, este índice está basado en columnas y el procesamiento de consultas llega a lograr ganancias de un 1000% respecto al almacenamiento basado en filas. La estructura lógica de un almacén de columnas es una tabla con filas y columnas, pero se almacena físicamente en formato de columnas.
Si nos centramos en el almacenamiento interno de los índices columnstore, debemos saber que cada file group será de 102.400 filas como mínimo y 1.048.576 filas como máximo. De esta manera, si tenemos una tabla con 2.100.000 de registros y creamos un índice basado en columnas sobre ella, se almacenará en 2 file groups de 1.048.576 cada uno y quedarán 2.848 filas, las cuales no son suficientes como para pertenecer a otro grupo de filas. Estas filas sobrantes se insertan en el almacén delta.
2.- ¿Qué es el Delta store?
Bien, para comprender qué es el almacén delta, vamos a basarnos en el ejemplo anterior.
Al tener 2 grupos de filas con 1.048.576 cada uno, nos quedan 2.848 filas que no son suficientes como para pertenecer a un nuevo file group, por lo tanto, dichas filas son almacenadas en el delta store, que no es más que un índice del tipo B-tree que se le añade al índice columnstore.
En el caso de cargas masivas de menos de 102.400 filas, éstas irán directamente al almacén delta.
Existe un “problema” al tener delta store abiertos, el dato no está comprimido y esto hace que se ralenticen las búsquedas sobre el índice columnstore. Por ello, es conveniente cerrar siempre los delta store.
Existen dos formas de cerrar los delta store:
- Realizar un rebuild del índice basado en columnas. Cuando se realiza una reconstrucción del índice, los delta store son cerrados y nos presentará una tabla completamente “segmentada”. Podría llevar mucho tiempo, dependiendo del particionamiento y del uso que le estemos dando. Un ejemplo de rebuild de un índice columnstore sería el siguiente:
- ALTER INDEX [Index_Name] ON [dbo].[Table] REBUILD PARTITION = ALL WITH (DATA_COMPRESSION = COLUMNSTORE);
- ALTER INDEX [Index_Name] ON [dbo].[Table] REORGANIZE WITH (COMPRESS_ALL_ROW_GROUPS = ON);
- Realizar una inserción masiva de filas. Si se realiza una inserción masiva de filas y éstas llegan al número máximo de filas del grupo de filas (1.048.576),éstas serán comprimidas y llevadas al índice basado en columnas mediante el proceso Tuple-Mover que veremos a continuación.
3.- Tuple-Mover
Este proceso comprueba los grupos abiertos de alrededor de 1 millón de filas que están preparados para ser comprimidos y añadidos al índice basado en columnas.
Para comprender el proceso anterior, vamos a basarnos en la siguiente imagen:
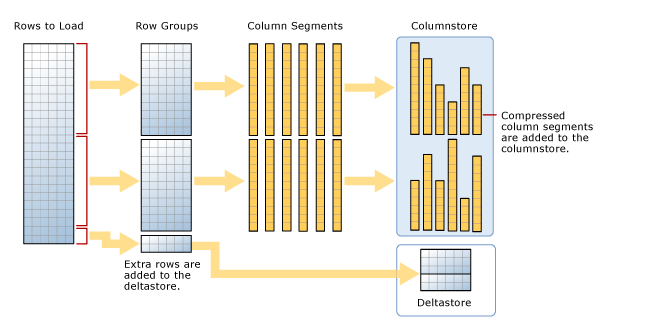
Como podemos observar, hay un número total de filas que se van a cargar, poniendo el ejemplo anterior, serán 2.100.000 filas.
Estas filas se dividirán en 2 grupos de filas de 1.048.576 que se comprimirán y formarán parte del índice basado en columnas, por lo tanto, quedarán 2.848 filas que serán almacenadas en el almacén delta al no llegar al mínimo de 102.400 filas para iniciar un nuevo grupo de filas.
Si realizamos una inserción de filas, estas serán sumadas a las filas en el delta store y al iniciar el proceso tuple-mover, si llega al millón de filas, éstas serán comprimidas y llevadas al índice basado en columnas.
Tip: En alguna versión de SQL Server, el tuple-mover no funciona correctamente cuando la tabla está siendo bloqueada por otro proceso como una Select. Por ello, se recomienda que se haga un rebuild del índice de forma manual cada vez que se se haga una inserción masiva de filas.
4.- Índice no agrupado de almacén de columnas
Un índice de almacén de columnas no agrupado y un índice de almacén de columnas agrupado funcionan del mismo modo. La diferencia es que un índice no agrupado es un índice secundario creado en una tabla de almacén de filas, pero un índice de almacén de columnas agrupado es el almacenamiento principal de toda la tabla.
A la hora de realizar una búsqueda, se puede hacer sobre el índice no agrupado de la tabla, que tiene parte de la tabla en su totalidad, pero éste realmente se hará sobre el índice agrupado de almacén de columnas. En nuevas entradas haremos hincapié en los índices de almacenamiento basados en columnas para análisis operativos a tiempo real.
Espero que os haya sido de ayuda!

Azure Data Engineer con más de 7 años de experiencia. Conocimiento de múltiples herramientas y enfocado en el mundo del dato. Experto en tuning de queries y mejora de rendimiento de Base de Datos. Profesional apasionado por la tecnología y los deportes al aire libre. En mi tiempo libre, me encontrarás jugando vóley playa o disfrutando con nuevos videojuegos.