
Vector Search en SQL Server 2025: tipo VECTOR y DiskANN

Introducción
Está claro que la IA ha venido para quedarse, y Microsoft lo sabe. Es por esto que la versión 2025 de SQL Server viene con una nueva característica para la era IA: La utilización de vectores para sus búsquedas. A estas alturas de 2026, palabras como ‘búsqueda semántica’ ya te sonarán familiares. Esta nueva característica nos proporciona una nueva forma de buscar y analizar datos, especialmente no estructurados, dentro del propio SQL Server.
Entendiendo los vectores y su funcionamiento
Un vector no es más que un tipo de dato que guarda una lista ordenada de números que representan datos complejos en un formato numérico que la IA puede entender y comparar.
Un vector embedding es una forma de convertir una oración, imagen, o prácticamente cualquier cosa, en un vector, es decir, una lista de números que lo representan. Estos números se representan en un espacio dimensional enorme, y están generados por modelos de machine learning que entienden el contexto de los datos.
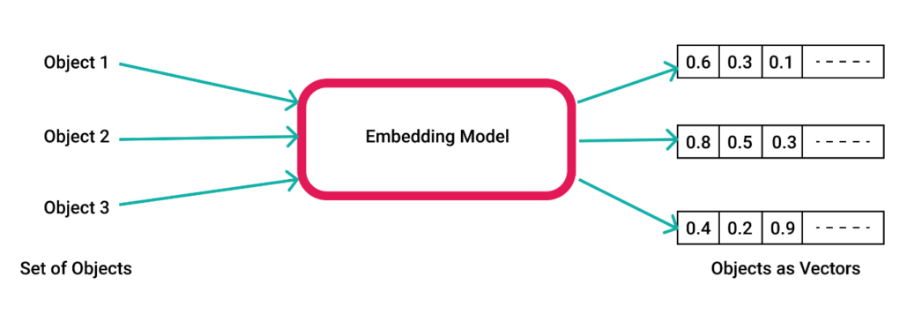
Cada dimensión del vector representa una característica del dato vectorizado. Por ejemplo, si vectorizamos una frase, cada una de las dimensiones de su vector representa algún matiz de su significado, su gramática o su contexto. Cuanto mayor sea el número de dimensiones, mejor será la comprensión de los datos, a costa de sacrificar rendimiento.
Esto hace que en lugar de buscar palabras exactas, se puedan buscar ‘ideas’. Por ejemplo, si tenemos datos de todos los Airbnbs de una provincia, podremos buscar ‘me gusta hacer surf’ sin necesidad de de que en el anuncio ponga explícitamente que están al lado del mar.
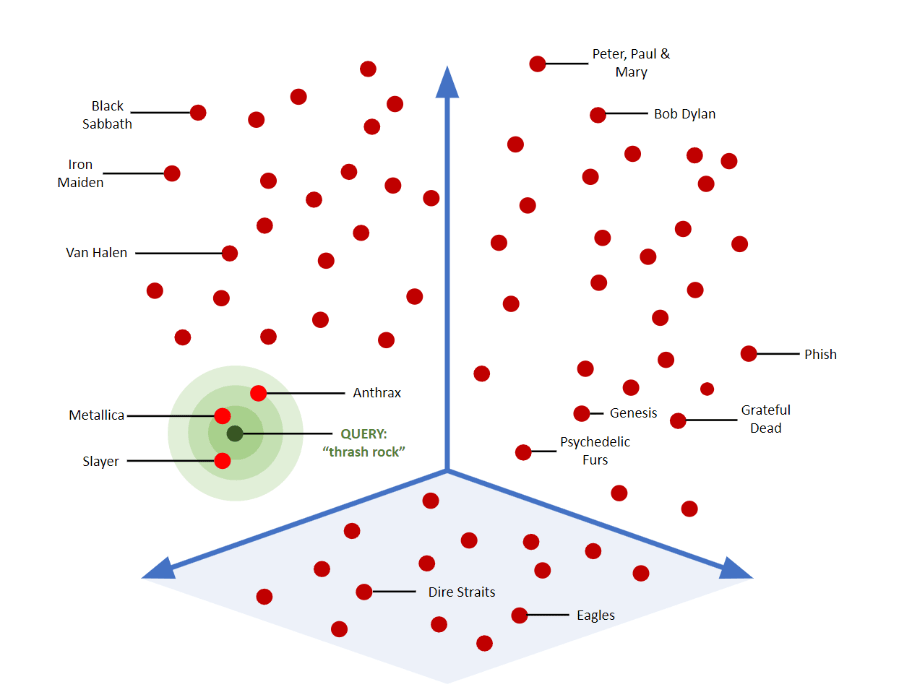
En la siguiente imagen, donde cada vector representa un grupo de música, podemos ver la proximidad con sus vecinos colindantes y cómo estarían distribuidos en un gráfico dimensional.
Implementación
SQL Server soporta ya el nuevo tipo de dato VECTOR, así que ahora podemos guardar los embeddings directamente en tablas.
Cada elemento del vector se almacena como un valor flotante de 4 bytes. El vector en sí se almacena en un formato binario optimizado pero se muestra como una array de JSONs por facilidad.
En el ejemplo que vamos a presentar, crearemos una tabla de artículos de IA con un campo VECTOR para guardar el embedding. Después, utilizaremos OpenAI para generar el embedding de a partir del campo que describe el artículo y crearemos un índice para realizar la búsqueda semántica y order los artículos en función de la distancia que tienen entre ellos, es decir, su similitud. Para ello, utilizaremos el algoritmo DiskANN (Disk-based Approximate Nearest Neighbor), desarrollado por Microsoft Research. Este algoritmo está diseñado para encontrar rápidamente los vecinos más cercanos en grandes conjuntos de datos utilizando poca memoria RAM y apoyándose principalmente en discos SSDS, aunque está diseñado para leer el disco muy pocas veces y de forma eficiente. No utiliza mucha memoria porque crea una estructura de tipo grafo donde cada vector se conecta con sus vecinos más cercanos.
Implementación de Vector Search con código
Lo primero que tenemos que hacer es activar la invocación externa del endpoint REST en nuestro SQL Server:
EXECUTE sp_configure 'external rest endpoint enabled', 1; RECONFIGURE WITH OVERRIDE; GO
Para poder crear credenciales, necesitamos crear primero una clave maestra, si no la tenemos ya:
IF NOT EXISTS (SELECT *
FROM sys.symmetric_keys
WHERE [name] = '##MS_DatabaseMasterKey##')
BEGIN
CREATE MASTER KEY ENCRYPTION BY PASSWORD = N'<password>';
END
GO
Después, creamos la credencial:
CREATE DATABASE SCOPED CREDENTIAL [https://<myendpoint>.openai.azure.com/]
WITH IDENTITY = 'HTTPEndpointHeaders', secret = '{"api-key":"....."}';
GO
Luego creamos un modelo externo para llamar al endpoint REST de embeddings de Azure OpenAI:
CREATE EXTERNAL MODEL MyAzureOpenAIModel
WITH (
LOCATION = 'https://<myendpoint>.openai.azure.com/openai/deployments/text-embedding-ada-002/embeddings?api-version=2023-05-15',
API_FORMAT = 'Azure OpenAI',
MODEL_TYPE = EMBEDDINGS,
MODEL = 'text-embedding-ada-002',
CREDENTIAL = [https://<myendpoint>.openai.azure.com/]
);
Con esto hecho, ya podemos crear la tabla con su embedding correspondiente llamando a la función AI_GENERATE_EMBEDDINGS:
CREATE TABLE dbo.Articles
(
id INT PRIMARY KEY,
title NVARCHAR(100),
content NVARCHAR(MAX),
embedding VECTOR(1536)
);
INSERT INTO dbo.Articles (id, title, content)
VALUES (1, 'Intro to AI', 'This article introduces AI concepts.'),
(2, 'Deep Learning', 'Deep learning is a subset of ML.'),
(3, 'Neural Networks', 'Neural networks are powerful models.'),
(4, 'Machine Learning Basics', 'ML basics for beginners.'),
(5, 'Advanced AI', 'Exploring advanced AI techniques.');
GO
UPDATE dbo.Articles
SET embedding = AI_GENERATE_EMBEDDINGS (content USE MODEL MyAzureOpenAIModel)

Una vez preparada la tabla, vamos a crear el índice para el vector correspondiente.
CREATE VECTOR INDEX vec_idx ON Articles(embedding) WITH (METRIC = 'cosine', TYPE = 'diskann'); GO
Como se puede observar, la métrica que utilizaremos para calcular la distancia entre dos vectores será el coseno (también podemos utilizar euclidean y dot), y el algoritmo que utilizaremos es DiskANN, que actualmente es el único soportado.
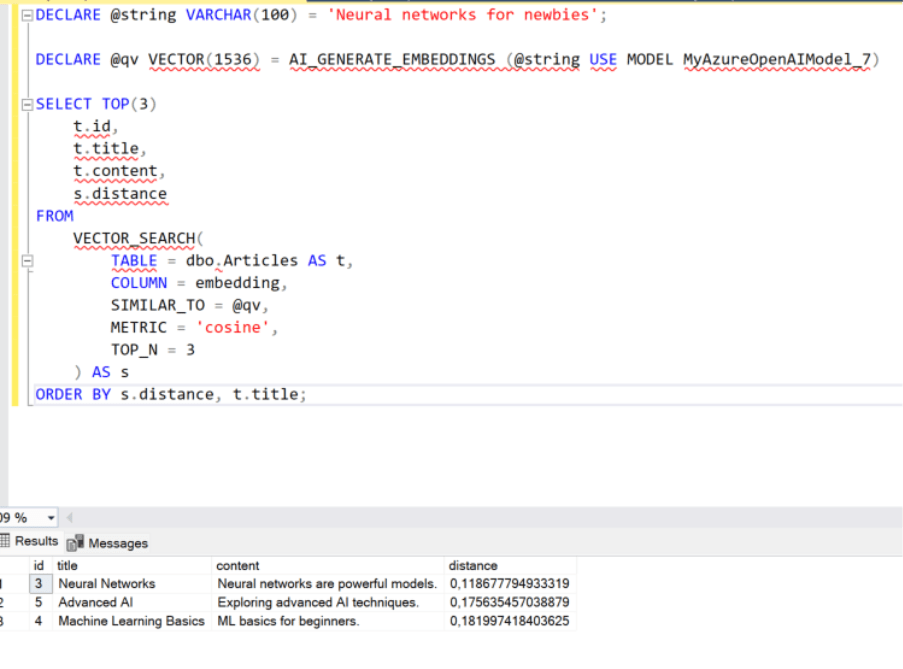
Por último, haremos una búsqueda semántica sobre los artículos para ver que, efectivamente, la IA entiende el contexto y nos saca los artículos más parecidos a lo que estamos buscando.

Por ejemplo, si buscamos ‘redes neuronales para principiantes’, nos sacará el artículo sobre redes neuronales pero también el de técnicas avanzadas de IA y machine learning para principiantes:
DECLARE @string VARCHAR(100) = 'Neural networks for newbies';
DECLARE @qv VECTOR(1536) = AI_GENERATE_EMBEDDINGS (@string USE MODEL MyAzureOpenAIModel_7)
SELECT TOP(3)
t.id,
t.title,
t.content,
s.distance
FROM
VECTOR_SEARCH(
TABLE = dbo.Articles AS t,
COLUMN = embedding,
SIMILAR_TO = @qv,
METRIC = 'cosine',
TOP_N = 3
) AS s
ORDER BY s.distance, t.title;
Esperamos que os haya servido de ayuda, no olvidéis ver el resto de artículos de la serie de novedades de SQL Server 2025.
Artículos de la Serie de SQL Server 2025
- Parte 1: Todas las novedades de SQL Server 2025
- Parte 2: Optimized Locking en SQL Server 2025
- Parte 3: Nuevo algoritmo compresión backup ZSTD para SQL Server 2025
- Parte 4: Change Event Streaming (CES) en SQL Server 2025
- Parte 5: SQL Server 2025 mejora el rendimiento de JSON con índices y nuevas funciones
- Parte 6: Vector Search en SQL Server 2025: tipo VECTOR y DiskANN
- Parte 7: Cómo usar expresiones regulares (REGEX) en SQL Server 2025
- Parte 8: Novedades de Intelligent Query Processing en SQL Server 2025
- Parte 9: Novedades de SQL Server Management Studio 22
- Parte 10: Data API Builder para Azure Databases

DBA SQL Server with 5 years of experience. Although I have advanced knowledge in various areas of SQL Server, I am also currently discovering MongoDB.