
Optimización de tablas Delta en Microsoft Fabric (Parte III): Table Features, Execution Plan y Native Execution Engine

En las entregas anteriores de esta serie (Parte I y Parte II) vimos cómo estructurar tablas Delta con particionamiento y estrategias de clustering. En esta tercera parte nos centramos en las configuraciones de tabla avanzadas, las herramientas de diagnóstico de rendimiento y la configuración óptima del entorno de ejecución en Microsoft Fabric.
Table Features: configuraciones avanzadas de tablas Delta
Al crear o mantener una tabla Delta, es posible activar una serie de propiedades que cambian significativamente su comportamiento. Para inspeccionar la configuración actual de cualquier tabla, basta con ejecutar:
DESCRIBE DETAIL nombre_esquema.nombre_tabla;
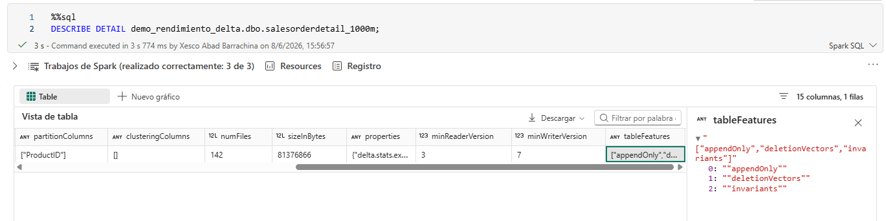
A continuación se describen las tres funcionalidades más relevantes.
Deletion Vectors
Los Deletion Vectors permiten realizar borrados lógicos sin reescribir los archivos Parquet subyacentes. En un flujo Delta estándar, eliminar filas obliga a reescribir los ficheros afectados. Con esta opción activada, Delta mantiene el archivo original y almacena una «máscara» que marca las filas invalidadas, reduciendo drásticamente el coste de escritura en operaciones de borrado masivo.
ALTER TABLE demo_rendimiento_delta.dbo.salesorderdetail_1000m
SET TBLPROPERTIES (
'delta.enableDeletionVectors' = true
);
AppendOnly
La propiedad AppendOnly restringe la tabla a operaciones de inserción exclusivamente. Es la configuración ideal para tablas de históricos o logs donde nunca se actualiza ni elimina ningún registro, ya que permite optimizaciones internas adicionales al garantizar que los datos solo crecen.
Invariants / Constraints
Los Invariants son restricciones de integridad que Delta aplica en cada operación de escritura. Son equivalentes funcionales a los CHECK CONSTRAINTS de SQL Server. Si un registro no cumple la restricción definida, la operación falla con un error explícito.
El siguiente ejemplo impide insertar filas donde LineTotal sea inferior a 50:
ALTER TABLE sales ADD CONSTRAINT chk_total CHECK (LineTotal >= 50);
Nota: A diferencia de otras propiedades, los constraints están activos por defecto en todas las tablas Delta y no requieren activación manual.
Execution Plan: diagnóstico de rendimiento en Spark
Al igual que en SQL Server, las tablas Delta permiten inspeccionar el plan de ejecución de una consulta antes de ejecutarla. Esto es fundamental para detectar lecturas innecesarias de columnas, ausencia de filtros de partición o joins costosos.
Para obtener el plan detallado, añade EXPLAIN FORMATTED antes de tu consulta:
EXPLAIN FORMATTED SELECT * FROM demo_rendimiento_delta.dbo.salesorderdetail_1000m WHERE ProductID = 870;

La siguiente tabla recoge los indicadores clave que conviene revisar en el plan:
| Indicador | Estado óptimo | Estado problemático | Descripción |
|---|---|---|---|
| Scan Parquet | Pocas columnas leídas | Muchas columnas innecesarias | Lectura física desde ficheros Delta/Parquet |
| PartitionFilters | Aparece | No aparece | Eliminación de particiones completas antes de leer |
| PushedFilters | Aparece | No aparece | Filtros enviados al almacenamiento para reducir datos leídos |
| Tipo de Join | BroadcastHashJoin | SortMergeJoin | Método de unión entre tablas |
| Exchange | Pocos | Muchos | Shuffles: movimiento de datos entre ejecutores |
| ReadSchema | Pocas columnas | Muchas columnas | Columnas efectivamente leídas del almacenamiento |
| AdaptiveSparkPlan | Sí | No | Indica si AQE está activo y optimizando el plan en tiempo real |
COMPUTE STATISTICS
En Delta, las estadísticas se actualizan automáticamente. No obstante, si el plan de ejecución muestra que el particionamiento definido no se está aplicando correctamente, puedes forzar su recálculo con:
ANALYZE TABLE demo_rendimiento_delta.dbo.salesorderdetail_1000m COMPUTE STATISTICS;
Este comando tiene menos impacto que
UPDATE STATISTICSen SQL Server, pero puede resolver inconsistencias puntuales en el optimizador de Spark.
Native Execution Engine
Configuración del entorno: Environment en Microsoft Fabric
Cada proyecto nuevo en Microsoft Fabric debe arrancar con la creación de un Environment propio. Este objeto centraliza las bibliotecas, funciones y parámetros de ejecución del proyecto.
Para crearlo: New item → Environment.
Una vez creado, navega a la sección Acceleration y activa el Native Execution Engine.
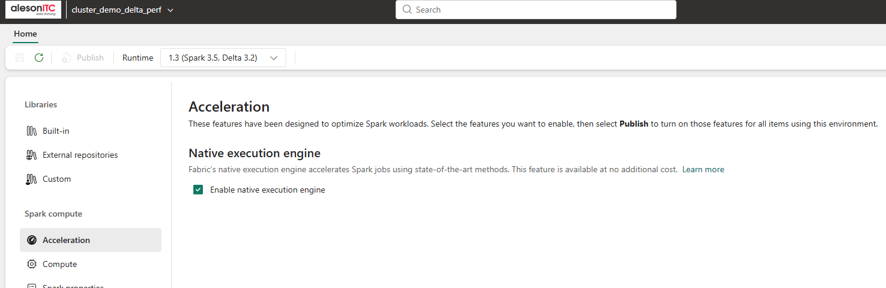
Qué es el Native Execution Engine
Por defecto, Spark ejecuta todas las operaciones a través de la JVM:
Query → Catalyst Optimizer → JVM Spark Engine → Parquet / Delta
Con el Native Execution Engine activado, ciertas operaciones se derivan a un motor nativo escrito en C++, basado en Apache Velox:
Query → Catalyst Optimizer → Native Engine (C++) → Parquet / Delta
Este motor está optimizado para consultas de tipo SQL analítico sobre tablas grandes (> 100 millones de filas), especialmente operaciones de agregación:
GROUP BYSUM/AVGCOUNT/COUNT DISTINCT
Cuándo no usar Native Execution Engine: en flujos con lógica Python personalizada, el motor debe abandonar el entorno nativo para volver a la JVM, lo que introduce overhead. Los siguientes casos se ven penalizados:
- UDFs Python
- Pandas UDF
- Código Python con lógica personalizada
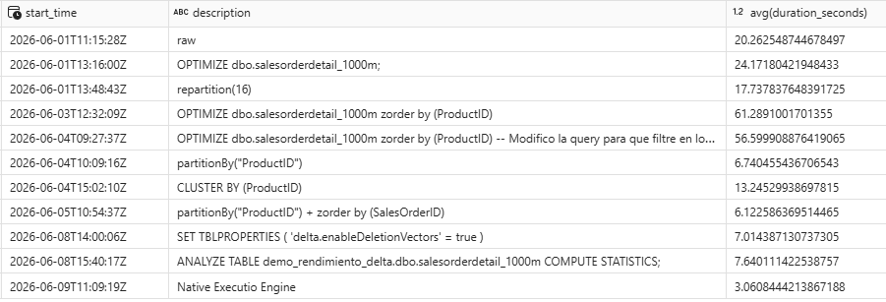
Resultados medidos
Tras activar el Native Execution Engine sobre una consulta ejecutada previamente con clusterBy(ProductID), los resultados fueron los siguientes:
| Configuración | Tiempo de ejecución |
|---|---|
clusterBy(ProductID) (sin NEE) | 6,12 segundos |
| Native Execution Engine activado | 3,06 segundos |
Una reducción del 50% en tiempo de respuesta sin modificar una sola línea de código de negocio.
Conclusión
Las herramientas descritas en esta serie —particionamiento, clustering, Deletion Vectors, planes de ejecución y el Native Execution Engine— constituyen el conjunto de técnicas que aplicamos en proyectos reales de Microsoft Fabric para reducir tiempos de consulta y optimizar el consumo de SKU. Menos capacidad de cómputo necesaria se traduce directamente en menor coste para las empresas.
Si conoces alguna herramienta adicional o tienes dudas sobre alguno de los puntos tratados, déjalo en los comentarios.
FAQ — Preguntas frecuentes sobre optimización de tablas Delta en Microsoft Fabric
¿Qué son los Deletion Vectors en Delta Lake y cuándo conviene activarlos?
Los Deletion Vectors son una propiedad de tabla Delta que permite registrar borrados de forma lógica sin reescribir los archivos Parquet originales. Son especialmente útiles cuando se realizan operaciones frecuentes de DELETE o MERGE sobre tablas grandes, ya que evitan el coste de reescritura completa de ficheros. Se activan mediante ALTER TABLE ... SET TBLPROPERTIES ('delta.enableDeletionVectors' = true).
¿Cómo ver el plan de ejecución de una consulta en Microsoft Fabric / Spark?
Añadiendo EXPLAIN FORMATTED antes de cualquier consulta SQL obtienes el plan lógico y físico completo. Los indicadores más importantes son PartitionFilters (filtrado por partición), PushedFilters (filtros enviados al almacenamiento) y el tipo de join empleado (BroadcastHashJoin es más eficiente que SortMergeJoin).
¿Qué es el Native Execution Engine de Microsoft Fabric y qué mejora aporta?
Es un motor de ejecución nativo basado en C++ y Apache Velox que sustituye al motor JVM de Spark para determinadas operaciones analíticas. Ofrece mejoras significativas en agregaciones (GROUP BY, SUM, COUNT) sobre tablas con más de 100 millones de filas. En pruebas propias, redujo el tiempo de ejecución de 6,12 a 3,06 segundos en una misma consulta.
¿Cuándo NO debo usar el Native Execution Engine en Fabric?
El Native Execution Engine no es beneficioso —e incluso puede añadir overhead— cuando el pipeline contiene UDFs Python, Pandas UDFs o lógica Python personalizada, ya que estas operaciones obligan al motor a salir del entorno nativo y volver a la JVM de Spark.
¿Qué diferencia hay entre COMPUTE STATISTICS en Delta y UPDATE STATISTICS en SQL Server?
Ambos actualizan las estadísticas que usa el optimizador para generar planes de ejecución eficientes. En Delta, las estadísticas se recalculan automáticamente, por lo que ANALYZE TABLE ... COMPUTE STATISTICS solo es necesario cuando el optimizador no aplica correctamente los filtros de partición definidos. Su impacto es menor que en SQL Server, donde las estadísticas obsoletas son una causa frecuente de planes subóptimos.
¿Cómo puedo reducir el consumo de SKU en Microsoft Fabric mediante optimización de Delta?
Combinando particionamiento adecuado (partitionBy o clusterBy), Deletion Vectors para evitar reescrituras innecesarias, Native Execution Engine para consultas analíticas y la revisión periódica de planes de ejecución, es posible reducir significativamente el tiempo de cómputo por consulta. Menos tiempo de ejecución equivale directamente a menor consumo de capacidad Fabric y, por tanto, a un menor coste operativo.
Si necesitas una revisión experta de tu arquitectura, el equipo de Data Analytics de Aleson ITC puede ayudarte.
Business Intelligence Expert Consultant. Specialising in creation of Data Warehouse, Fabric, Analysis Services, Databricks, Power BI, SSIS and SSRS.