
🔍 Detectando y clasificando datos personales con SQL Server – Serie GDPR (2/5)

El primer paso para cumplir con el GDPR es evaluar si este aplica a tu organización y de ser así, que datos son los que deben ajustarse para cumplirlo. Para realizar este análisis, es necesario conocer que datos se tiene y donde están ubicados. Tener un esquema de clasificación de datos puede ayudar a responder a solicitudes de acceso a datos personales de una forma más rápida y controlada.
SQL Server cuenta con diversas herramientas que te pueden ayudar a descubrir y clasificar estos datos personales:
- Se pueden ejecutar consultas a tablas de sistema y metadatos para identificar de una forma rápida si una columna tiene datos personales o no.
- Si se tienen campos de texto libre, como el típico “Observaciones”, se pueden utilizar búsquedas de tipo Full-Text para encontrar datos de carácter personal.
- Podemos utilizar la característica Propiedades Extendidas para etiquetar y añadir una descripción a los campos o tablas que contengan datos personales. A partir de la versión 17.5 de SQL Server Management Studio se ha añadido una funcionalidad que nos ayudará a realizar esta clasificación de una forma muy fácil.
Detectar
Lo ideal para poder detectar que columnas pueden contener información personal es tener una buena documentación de la base de datos para saber de una manera rápida las tablas que están implicadas, lamentablemente estamos en el mundo real y el 90% de las veces esta documentación no existe o está obsoleta, por lo que aquí viene SQL Server y su tabla sys.columns para ayudarnos.
Si no conocías la tabla sys.columns, una descripción rápida sería “Es una tabla de sistema que alberga información de todas las columnas de los objetos de una Base de datos, como pueden ser tablas o vistas”, si necesitas más información, aquí tienes el link a la documentación oficial sys.columns (Transact-SQL).
Por ejemplo, para poder saber todas las columnas de una base de datos que contengan la palabra “nombre” podríamos ejecutar la siguiente consulta:
SELECT object_name(object_id) AS TableName,
Name as ColumnName
FROM sys.columns
WHERE name LIKE '%nombre%'Partiendo de esa base, hemos creado un pequeño script que empieza con una tabla temporal a modo de diccionario en la que pondremos todas las palabras que queremos buscar (en este caso palabras candidatas a albergar información personal) y luego mediante cursores buscará esas palabras en todas las base de datos y las guardará en otra tabla temporal que se mostrará al final.
Es importante remarcar que en el script puedes añadir nuevas palabras que quieras buscar, no importa que sean en mayúsculas o minúsculas o con o sin acentos, que las encontrará.
/*--------------------------------------------------------------------------------------
-- Título: Usando sys.columns para descubrir columnas que alberguen datos personales - GDPR
-- Autor: Fran Lens - Aleson ITC (https://aleson-itc.com)
-- Fecha: 2018-06-22
-- Descripción: Este script nos ayudará a descubrir columnas que puedan contener datos personales, por defecto
busca unas cuantas palabras candidatas en Español e Inglés, pero se pueden añadir las que queramos.
Puedes poner las palabras en mayúsculas o minúsculas o con o sin acentos, que las encontrará.
--------------------------------------------------------------------------------------*/
-- Declaración de variables
DECLARE @DatabaseName nvarchar(100)
, @Word nvarchar(50)
, @SQL nvarchar(max)
-- Borra la tabla #Words si existe
IF OBJECT_ID('tempdb.dbo.#Words', 'U') IS NOT NULL
DROP TABLE #Words;
-- Borra la tabla #DiscoverGDPR si existe
IF OBJECT_ID('tempdb.dbo.#DiscoverGDPR', 'U') IS NOT NULL
DROP TABLE #DiscoverGDPR;
-- Creación de tabla #Words
CREATE TABLE #Words (word nvarchar(50))
-- Creación de tabla #DiscoverGDPR
CREATE TABLE #DiscoverGDPR (DatabaseName nvarchar(100), SchemaName nvarchar(100), TableName nvarchar(100), ColumnName nvarchar(100))
-- Insertamos palabras a buscar en la tabla #Words
INSERT INTO #Words VALUES
-- Spanish
('Nombre')
,('Apellido')
,('Tel') -- Aquí cogería valores como Telefono y abreviaturas
,('Tfno')
,('Direccion')
,('Poblacion')
,('Ciudad')
,('Pais')
,('Postal') -- Aquí cogería valores como CodigoPostal, DireccionPostal, DestinoPostal
,('CP')
,('Nac') -- Aquí cogería valores como Nacionalidad, FechaNacimiento, LugarNacimiento
,('DNI')
,('CIF')
,('NIE')
,('Pasaporte')
,('Identifi')
,('Mail') -- Aquí cogería valores como Mail, Email, Correo Mail
,('Correo') -- Aquí cogería valores como Correo, CorreoElectronico
,('Foto') -- Aquí cogería valores como Foto, Fotografia
,('Banco')
,('Tarjeta')
,('Cuenta')
,('Numero') -- Aquí cogería valores como NumeroCuenta, NumeroTelefono
,('IP')
-- English (Algunos términos de Spanish también son válidos, como Postal o Identifi)
,('Name')
,('Surname')
,('Phone') -- Aquí cogería valores como Phone, PhoneNumber, Cellphone
,('Mobile')
,('Cell')
,('Celular')
,('Address')
,('City')
,('Country')
,('ZIP')
,('Code')
,('Birthday')
,('Passport')
,('Photo')
,('Bank')
,('Card')
,('Account')
,('Number')
,('IP')
-- Creamos un cursor con las Bases de Datos en las que queremos buscar la información
DECLARE db_cursor CURSOR
FOR
SELECT name
FROM master.sys.databases
WHERE name NOT IN ('master', 'model', 'msdb', 'tempdb', 'distribution');
-- Iniciamos cursor db_cursor
OPEN db_cursor
-- Avanzamos cursor db_cursor
FETCH NEXT FROM db_cursor INTO @DatabaseName;
-- Loop db_cursor
WHILE @@FETCH_STATUS = 0
BEGIN
-- Creamos un cursor que recorra la tabla #Words
DECLARE Word_Cursor CURSOR FOR
SELECT * FROM #Words
-- Iniciamos cursor Word_Cursor
OPEN Word_Cursor
-- Avanzamos cursor Word_Cursor
FETCH NEXT FROM Word_Cursor INTO @Word
-- Loop Word_Cursor
WHILE @@FETCH_STATUS = 0
BEGIN
-- Creamos la sentencia
SET @SQL = 'USE ' + @DatabaseName + ';' +
'INSERT INTO #DiscoverGDPR ' +
'SELECT ''' + @DatabaseName + ''' AS [database], ' +
' SCHEMA_NAME(schema_id) AS [schema], ' +
' t.name AS table_name, c.name AS column_name ' +
'FROM sys.tables AS t ' +
'INNER JOIN sys.columns c ON t.OBJECT_ID = c.OBJECT_ID ' +
'WHERE c.name LIKE ''%'+ @Word +'%'' COLLATE SQL_Latin1_General_CP1_CI_AI'
-- Ejecutamos sentencia
EXEC sp_executesql @SQL
-- Avanzamos cursor Word_Cursor
FETCH NEXT FROM Word_Cursor INTO @Word
END
-- Cerramos y borramos cursor Word_Cursor
CLOSE Word_Cursor
DEALLOCATE Word_Cursor
-- Avanzamos cursor db_cursor
FETCH NEXT FROM db_cursor INTO @DatabaseName;
END
-- Cerramos y borramos cursor db_cursor
CLOSE db_cursor;
DEALLOCATE db_cursor;
-- Mostramos los datos
SELECT *
FROM #DiscoverGDPR
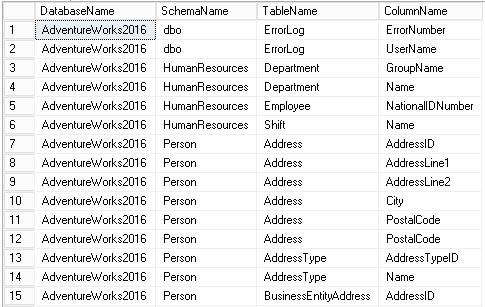
ORDER BY DatabaseName, SchemaName, TableName, ColumnNameAquí podemos ver los resultados que devolvería la base de datos AdventureWorks2016:
Clasificar
Una vez que tenemos detectadas las columnas que contienen datos de carácter personal, el siguiente paso que debemos tomar es clasificaras según el tipo de datos que almacenen, para esto contamos con las Propiedades Extendidas de las columnas.
Las Propiedades Extendidas están disponibles desde SQL Server 2008 y es una forma de añadir una descripción o una clasificación a cada columna, para acceder a esa características solo tendremos que pulsar botón derecho sobre una columna y pinchar en propiedades.
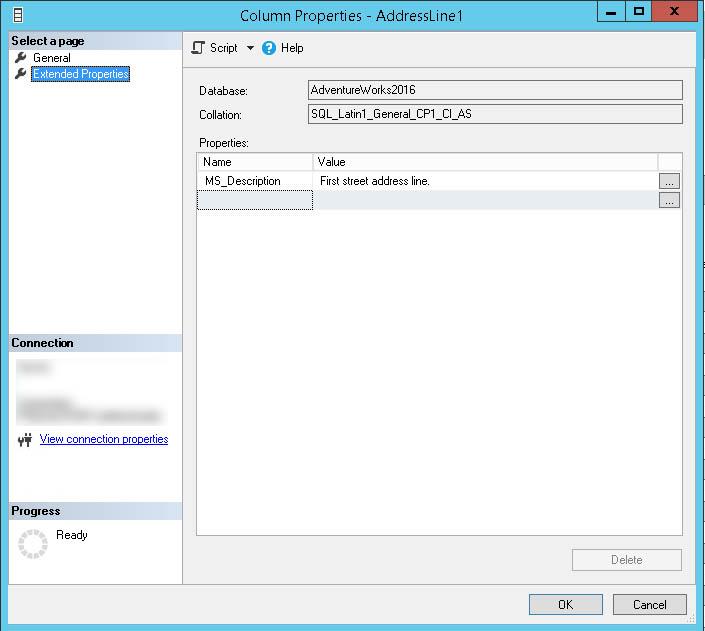
Ahora os encontráis en ese momento que pensáis que si hay que hacer esto columna a columna os vais a tirar un siglo, pero no os alarméis, hay una solución que hará este proceso mucho más rápido y hasta un poco automatizado y que está disponible desde la versión 17.5 de SQL Server Management Studio.
Podemos acceder a esta opción dando click derecho encima de una base de datos->Tasks->Classify Data…
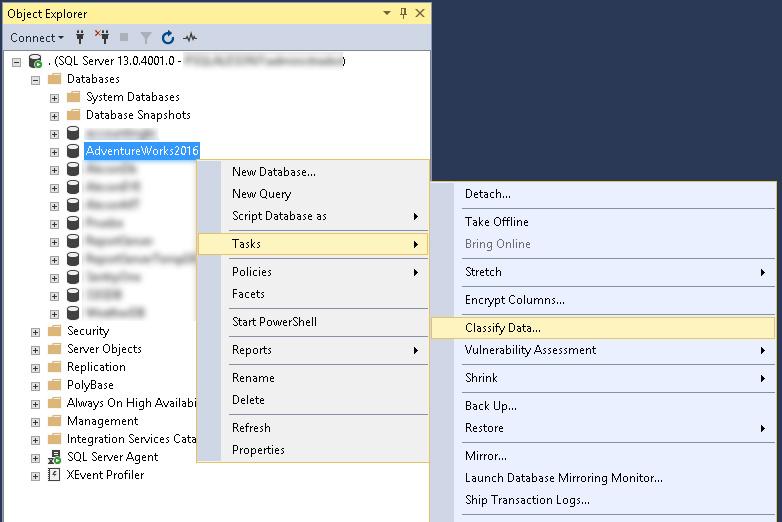
Nada más abrirlo, y de forma automática ya nos hará una recomendación de clasificación de determinadas columnas.

Al pinchar, nos aparecerá la lista de columnas.
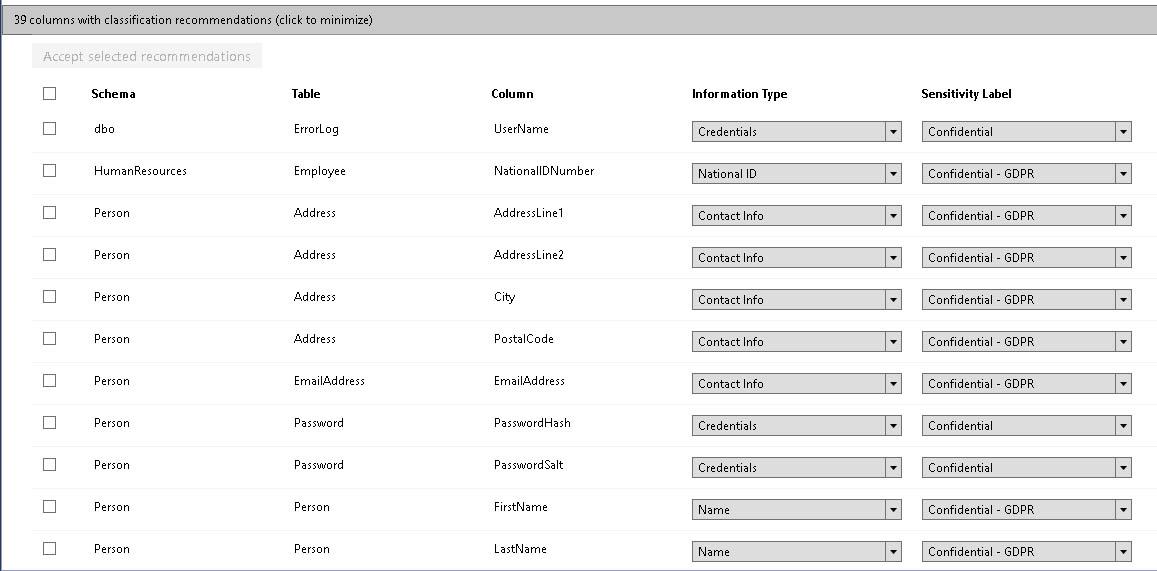
Podemos seleccionar las columnas que queramos y pinchar en “Accept selected recommendations“. Está acción lo que hará es añadir el Information Type y el Sensibility Label a las Propiedades Extendidas de la columna.
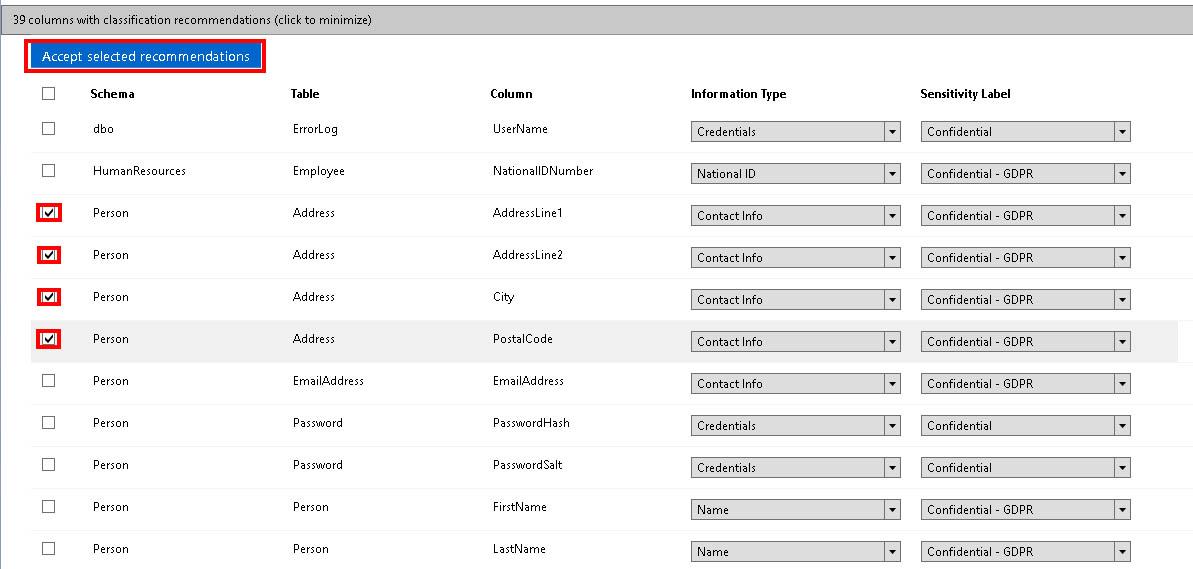
Una vez que acabemos con las columnas sugeridas, nos apoyaremos en la lista que habremos sacado con nuestro script en la fase de detección para clasificar otras columnas.
La clasificación se hará eligiendo un Information type y un Sensitivity Label, dentro de cada uno encontraremos los siguientes tipos:
Information Type:
- Banking
- Contact Info
- Credentials
- Credit Card
- Date Of Birth
- Financial
- Health
- Name
- National ID
- Networking
- SSN
- Other
- [n/a]
Sensitivity Label:
- Public
- General
- Confidential
- Confidential – GDPR
- Highly Confidential
- Highly Confidential – GDPR
- [n/a]
Ahora que ya hemos detectado y clasificado nuestros datos personales, podemos lanzar un reporte que nos enseñe datos estadísticos de esta clasificación de una forma rápida.
Accedemos a este reporte dando click derecho encima de una base de datos->Reports->Standard Reports->Data Classification
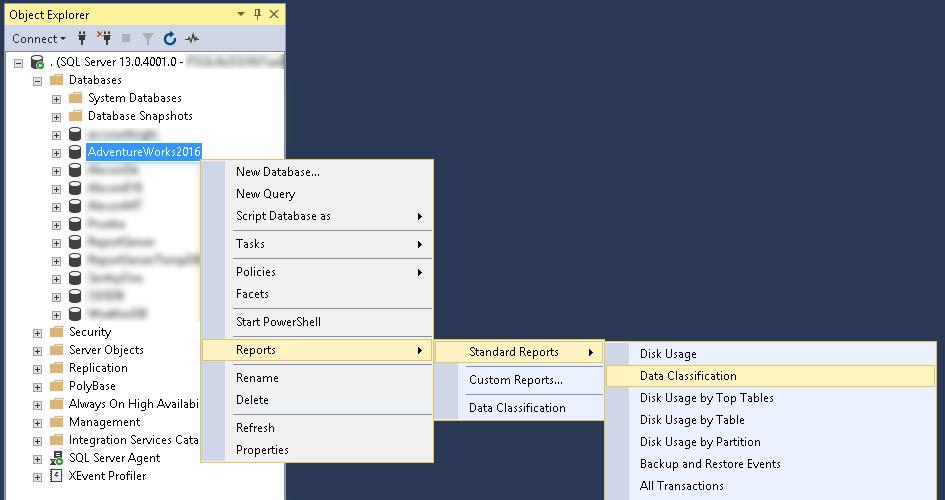
En nuestro caso únicamente veremos en el report 4 columnas, que son las que habíamos marcado previamente con la herramienta Classify Data.
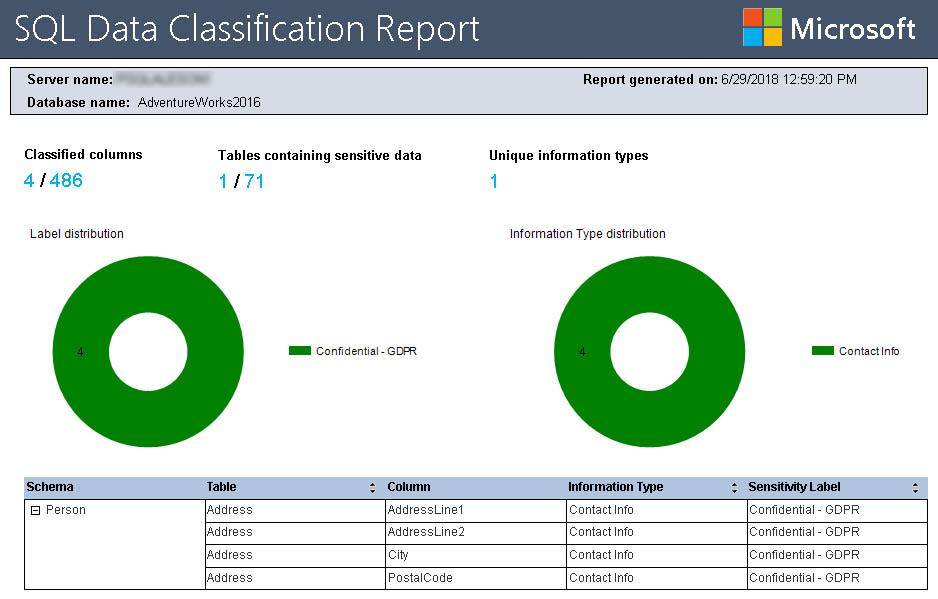
Ahora que ya tenemos todas nuestras columnas perfectamente clasificadas, es hora de ir al siguiente punto del GDPR y ver como Administrar estos datos.
Serie completa de GDPR:
- Cómo adaptar SQL Server al RGPD (GDPR)
- Detectando y clasificando datos personales con SQL Server
- Administrando los accesos y el uso de los datos con SQL Server
- Protegiendo datos en Reposo, en Uso y en Tránsito
- Monitorizar y Reportar accesos no autorizados a Datos Personales

Working with data technologies since 2008, my main expertise is in SQL Server but I work well as a Data Engineer in Azure Data and in all kinds of databases. Since 2015 I work at Aleson ITC, a company where I am the CTO and also a shareholder.