
Azure Data Explorer and Kusto Query Language

Welcome to a new post on the best SQL Server blog. In today’s post we’ll talk about Azure Data Explorer, an Azure’s analytics platform. But first, I’m going to explain what it’s and how it works.
Let’s start!
What is Azure Data Explorer?
Azure Data Explorer is a managed data analytics platform, with excellent performance and fully scalable that allows us to study large amounts of data in near real time. The source of that data can be as diverse as applications, websites or even IoT devices.
Through data analysis and Machine Learning, Azure Data Explorer makes it easier for us to draw conclusions, detect patterns and trends, and create forecast models.
When we use Azure Data Explorer?
Azure Data Explorer is a fully optimized service that will be very useful especially in the following cases:
- When it’s a requeriment of the solution that it has to be interactive. That is, make it easier for non-experts to analyze complex situations represented in the form of data.
- In cases where there are large amounts of data and treating them in real time.
- If you don’t have processed data.
- When there are simultaneous queries.
- In cases where you want to customize the data platform.
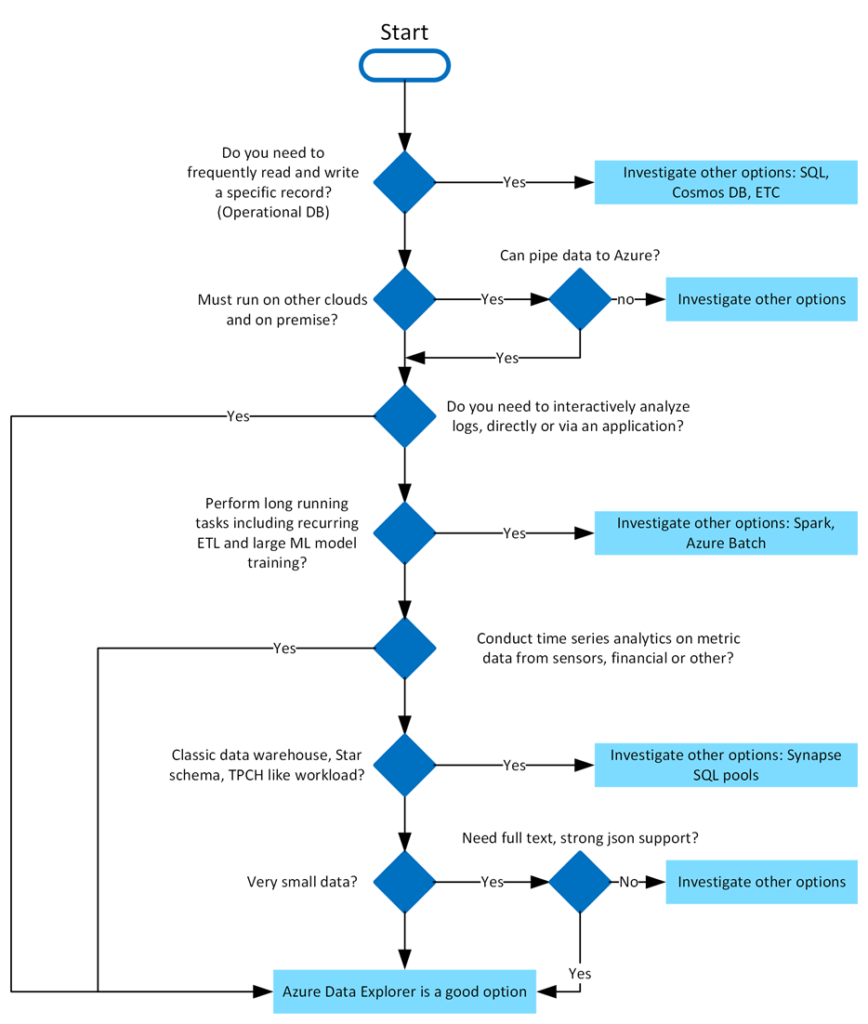
What makes Azure Data Explorer special?
Data oriented
You can query large volumes of data and get results almost instantly. Azure Data Explorer also provides high speed, low latency, and raw data ingestion, that is, data in different formats and structures, coming from multiple and diverse sources.
Tools for advanced analysis
Azure Data Explorer enables time series analysis with a rich set of tools such as time series aggregation/subtraction, filtering, regression, geospatial analysis, anomaly detection, examination and forecasting. These tools are optimized to process thousands of data in a matter of seconds.
Intuitive data ingestion wizard
The data ingestion wizad is simple, fast and easy to use. It has a guided experience that helps the user to ingest data and automatically create and assign structures, such as tables or schemas. Additionally, it enables continuos or one-time data ingestion from multiple sources with diverse data formats. Also includes continuos export to Azure Data Lake Store.
Data visualization
Data visualization is a key aspect for the user to draw important conclusions. Azure Data Explorer enables the creation and visualization of dashboards with support for other platforms such as Microsoft Power BI, native connectors for Grafana, and ODBC support for Tableau.
Query language
The open source Kusto Query Language (KQL), invented by the development team, is used to collect information about Azure Data Explorer. Easy to understand and learn, it is a highly productive language that can use simple operators and advanced analysis. Python code can even be inserted into KQL queries to extend functionality.
Study Cases
Now, I’m going to show you some practical examples of managed data plaftorm queries.
Case Study 1: Kusto Queries

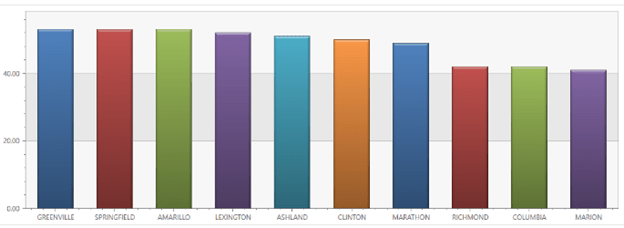
StormEvents database was used, which is the official database of NOAA’s National Weather Service (NWS). This database collects weather events from January 1950 to July 2022.
In the script above, events are counted by location and a graph is generated with the top 10 locations where the most events have ocurred.
Result:
Case Study 2: Inserting Python code into Kusto Query Language

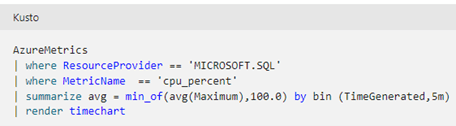
It’s possible to collect internal Azure metrics to generate graphs showing the evolution of the percentage of CPU usage, for example.
Case Study 3: Collecting metrics on CPU usage with KQL
Case Study 4: KQL and SQL
To ease the transition and learning, Kusto can be used to translate SQL queries to KQL.

And what is really running:
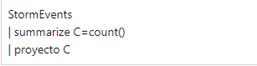
And to finish this post, I would like to share some equivalences between SQL and it’s equal in KQL
| IInstruction | SQL | KQL |
| Select all data from a table | SELECT * FROM dependencies | Dependencies |
| select some columns from a table | SELECT name, resultCode FROM dependencies | Dependencies | project name, resultCode |
| Comparisons | SELECT * FROM dependencies WHERE type = “Azure Blog” | Dependencies | where type == “Azure Blog” |
| Aggregation | SELECT AVG(duration) FROM dependencies GROUP BY name | Dependencies | summarize avg(duration) by name |
| Join | SELECT * FROM dependencies LEFT JOIN exception ON dependencies.operation_Id = exceptions.operation_Id | Dependencies | join kind = lefouter (exceptions) on $left.operation_Id == $right.operation_Id |
| Top n by aggregation | SELECT TOP 100 name, COUNT(*) as Count FROM dependencies GROUP BY name ORDER BY Count DESC | Dependencies | summarize Count = count() by name | top 100 by Count desc |
And with this table, we end today’s post. I hope it will help you when you start using Azure Data Explorer.
If you are interested in Microsoft technology and you are just starting out in the world of Azure, you can not miss these posts:
How to create automated tasks in Azure for virtual machines
Improve Managed Instance performance even more
How to create automated tasks in Azure for Virtual Machines
And if you need help with your Workload Migration to the cloud project, visit our Azure for Business page.

DBA SQL Server with 5 years of experience. Although I have advanced knowledge in various areas of SQL Server, I am also currently discovering MongoDB.