
Discover the main functionalities of SQL Server Always On Cluster
Welcome to a new post of this Blog. In today’s post we are going to talk about the SQL Server Always On Cluster. What is? What is its main function? Keep reading if you want to know more.
What is Cluster Failover?
A failover cluster is a set of servers, working together, to provide high availability (HA). If one of the servers goes down, another node in the cluster can take over its workload with minimal or no downtime through a process called failover, this is thanks to the quorum token, which can be a shared folder or an ISCSI (Internet Small Computer System Interface), which is responsible for checking for this inactivity.
What is Always On?
This is a high availability feature alternative to Database Mirroring that allows to ensure the availability of a set of databases.
Each availability group that is defined can host several databases, in case of failure of the main one, all the databases of the group would be moved to another node.
A remarkable feature is the possibility of configuring some of the replicas as read-only queryable. The solution allows us to have a primary and up to 8 secondary servers, also each of the replicas must reside on an independent node of a Windows Server failover cluster, other features to consider are the allowed synchronization modes.

Main advantages:
- Supports alternative availability modes such as the following:
- Asynchronous commit mode. This availability mode is a disaster recovery solution that works well when availability replicas are distributed over considerable distances.
- Synchronous commit mode. This availability mode provides high availability and performance data protection, at the cost of increased transaction latency. A given availability group can support up to five synchronous commit availability replicas, including the current primary replica.
- Supports several forms of failover of an Availability Group: automatic failover, planned manual failover (often referred to simply as “manual failover”), and forced manual failover (often referred to simply as “forced failover”).
- Allows you to configure a given availability replica that supports one or two of the following active secondary functions:
- Have read-only connection access, which allows read-only connections to the replica to access and read its databases when running as a secondary replica.
- Perform backup operations on your databases when running as a secondary replica.
- Supports one availability group listener agent for each availability group. An availability group listener agent is a server name that clients can connect to in order to have
OTHER SOLUTIONS
| Name | Description | Inconvenient |
| CLUSTER FAILOVER INSTANCE | It is a very similar term, which tries to provide the same characteristics of high availability and scalability, through an ISCSI (Internet Small Computer System Interface), which will allow us to store our SQL Server, in an ISCSI destination, as if it were a unit, which is connected to our computers. Previously it was used much more frequently in companies. | It works based on instances. That is to say, if an instance goes down, the other server with the same shared database comes into action, which means that if the ISCSI target is damaged for any reason, we are left without service. |
| LOG SHIPPING | It creates log backups, which it stores in a local folder, and copies it to a shared folder (which is sometimes the same), then copies the log file from the shared folder to the local folder of the secondary, then restores the log file from the local folder of the secondary. In short, a full manual backup is created and log shipping is configured, which, through the agents, restores backup logs from the primary server to the secondary server. | But it is not high availability, because in case of failure, we have to carry out a manual process of restoration and validation, which will take time and is not convenient. |
| DATABASE MIRRORING | It consists of having a single replica node, either in a separate server, or sharing the same storage, which will be synchronized and waiting until it receives an order, where it indicates that the node 1 fell, for this you need another server that is responsible for managing it automatically, otherwise it must be manual. | The main disadvantages that it may have are: Replica 2 cannot be read. Only one node can be |
Scenarios:
- Within a domain we have two servers with their respective SQL Server, which we will put in Cluster.
- Then we configure within the main SQL, the availability groups feature and select the databases that we want to be in the second node, then the token and the type of synchronization, for example synchronous.
- As a result we would have two nodes (they could also be up to 8 nodes) that are synchronized, which confirm that the information has arrived from node 1 to node 2 and has been restored correctly. It is also worth mentioning that in case of a node 1 failure, it would balance and node 2 would come into action, and we could also perform read actions on the secondary server, distributing the load.
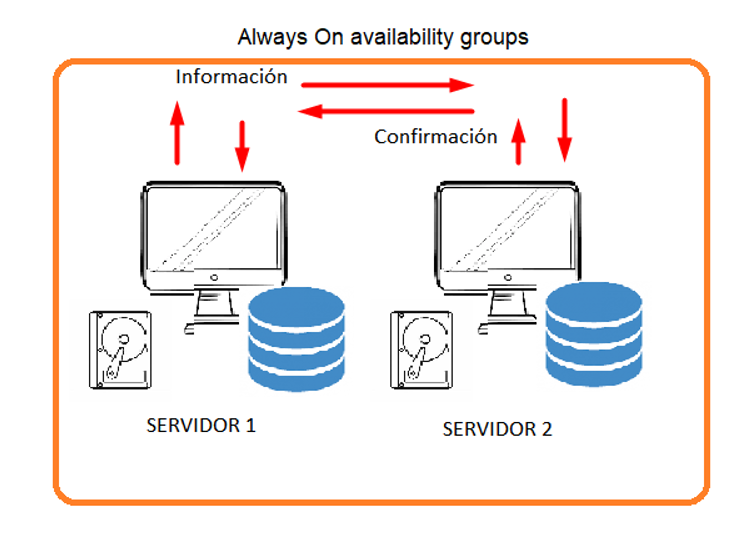
And that’s it for today’s post, I hope it has helped you understand Always ON Clusters.
If you want us to help you with your DB project, contact us.
I am a data engineer with experience in SQL Server and data analysis. I am certified in database administration and specialized in designing efficient and secure environments for database applications. My approach includes the application of analysis techniques to extract valuable information and support strategic decision making.
